Welcome to MDGSF's Blog!
This is my github blog-
如何选取 android 系统上的编译工具链
先介绍一些基础背景知识。
- Intel. 我们一般买的电脑都是 Intel 的 CPU。
- AMD. AMD 是 Intel 的最大竞争对手。AMD 的 CPU 一般也用在电脑上。
- ARM. ARM 的芯片一般用在手机、平板上。我的手机就是高通骁龙的。
ARM 有两层含义:
- ARM. 是一家半导体芯片设计研发的企业。
- ARM. 是与 x86 平级的 CPU 架构。
ARM CPU 架构与 x86 CPU 架构的区别:
- ARM CPU 架构使用 RISC(精简指令集)。
- x86 CPU 架构使用 CISC(复杂指令集)。
每个 CPU 都会实现一套指令集,也叫做 Instruction Set Architecture,简称 ISA。
标题上的这些名字表示的是不同平台的 CPU 架构。
- arm,arm32,armv7 是 32 位 ARMv7 架构。
- arm64,aarch64 是 64 位 ARMv8 架构。
- x86,i386,i686 是 32 位 Intel x86 架构。
- x86_64,amd64 是 64 位 Intel x86 架构。
现在的手机和电脑一般都是 64 位的,所以如果要给手机编译一个软件,一般使用 aarch64 类型的交叉编译工具链。
交叉编译工具链三元组格式介绍
Triple 三元组格式:
{arch}-{vendor}-{sys}-{abi}明明是 4 个项,不知道为什么叫三元组。
例子:
arm-unknown-linux-gnueabihf- 架构(architecture):arm。
- 供应商(vendor):unknown。这里 unknown 就是未指定供应商或者是不重要。
- 系统(system):linux。
- ABI:gnueabihf。gnueabihf 表示系统使用 glibc 作为其 C 标准库 libc 实现, 并且具有硬件加速浮点算法。
然后有的 triple 三元组会把供应商(vendor)或 ABI 给省略掉。例如:
x86_64-apple-darwin- 架构(architecture):x86_64。
- 供应商(vendor):apple。
- 系统(system):darwin。
那我们要怎么确定我们要用哪一个呢?
- 架构(architecture):在 UNIX 系统上,我们可以使用
uname -m查看。 - 供应商(vendor):Linux 通常是
unknown,Windows 是pc,OSX/IOS 是apple。 - 系统(system):在 UNIX 系统上,我们可以使用
uname -s查看。 - ABI:Linux 上可以使用
ldd --version查看。Mac 和 *BSD 忽略这个选项。Windows 是gnu或msvc。
因为我们是要给 64 位的 android 系统使用,所以一定要有 aarch64 和 android 出现,这样就可以排除掉其他不可以使用的了。 下面我们看具体要怎么选。
android 编译工具链
你可以从 ndk 下载 地址下载最新的 ndk。目前最新的稳定版本是 r21b。 我这里是 ubuntu 系统,所以下载
android-ndk-r21b-linux-x86_64.zip这个压缩包。 解压之后得到android-ndk-r21b这个目录,比如就解压到HOME目录/home/huangjian下面。我们可以编写一个如下的编译脚本,来编译最简单的 hello world 的 cpp 程序。
export NDK=/home/huangjian/android-ndk-r21b export TOOLCHAIN=$NDK/toolchains/llvm/prebuilt/linux-x86_64 export TARGET=aarch64-linux-android export API=29 export AR=$TOOLCHAIN/bin/$TARGET-ar export AS=$TOOLCHAIN/bin/$TARGET-as export CC=$TOOLCHAIN/bin/$TARGET$API-clang export CXX=$TOOLCHAIN/bin/$TARGET$API-clang++ export LD=$TOOLCHAIN/bin/$TARGET-ld export RANLIB=$TOOLCHAIN/bin/$TARGET-ranlib export STRIP=$TOOLCHAIN/bin/$TARGET-strip echo 'AR = '$AR echo 'AS = '$AS echo 'CC = '$CC echo 'CXX = '$CXX echo 'LD = '$LD echo 'RANLIB = '$RANLIB echo 'STRIP = '$STRIP $CC hello.cpp -o hello我们可以看到在目录
/home/huangjian/android-ndk-r21b/toolchains/llvm/prebuilt/linux-x86_64/bin下面,有非常多的不同 CPU 架构的编译器,我们需要选择其中一个来使用。上面的编译脚本中, 我们选择的是aarch64-linux-android29-clang。数字 29 是 API 的级别,详见 什么是 API 级别?。aarch64-linux-android21-clang armv7a-linux-androideabi23-clang ld.lld aarch64-linux-android21-clang++ armv7a-linux-androideabi23-clang++ lldb-argdumper aarch64-linux-android22-clang armv7a-linux-androideabi24-clang llvm-addr2line aarch64-linux-android22-clang++ armv7a-linux-androideabi24-clang++ llvm-ar aarch64-linux-android23-clang armv7a-linux-androideabi26-clang llvm-as aarch64-linux-android23-clang++ armv7a-linux-androideabi26-clang++ llvm-cfi-verify aarch64-linux-android24-clang armv7a-linux-androideabi27-clang llvm-config aarch64-linux-android24-clang++ armv7a-linux-androideabi27-clang++ llvm-cov aarch64-linux-android26-clang armv7a-linux-androideabi28-clang llvm-dis aarch64-linux-android26-clang++ armv7a-linux-androideabi28-clang++ llvm-lib aarch64-linux-android27-clang armv7a-linux-androideabi29-clang llvm-link aarch64-linux-android27-clang++ armv7a-linux-androideabi29-clang++ llvm-modextract aarch64-linux-android28-clang bisect_driver.py llvm-nm aarch64-linux-android28-clang++ clang llvm-objcopy aarch64-linux-android29-clang clang++ llvm-objdump aarch64-linux-android29-clang++ clang-check llvm-profdata aarch64-linux-android-addr2line clang-cl llvm-ranlib aarch64-linux-android-ar clang-format llvm-readelf aarch64-linux-android-as clang-tidy llvm-readobj aarch64-linux-android-c++filt clang-tidy.real llvm-size aarch64-linux-android-dwp dsymutil llvm-strings aarch64-linux-android-elfedit git-clang-format llvm-strip aarch64-linux-android-gprof i686-linux-android16-clang llvm-symbolizer aarch64-linux-android-ld i686-linux-android16-clang++ sancov aarch64-linux-android-ld.bfd i686-linux-android17-clang sanstats aarch64-linux-android-ld.gold i686-linux-android17-clang++ scan-build aarch64-linux-android-nm i686-linux-android18-clang scan-view aarch64-linux-android-objcopy i686-linux-android18-clang++ x86_64-linux-android21-clang aarch64-linux-android-objdump i686-linux-android19-clang x86_64-linux-android21-clang++ aarch64-linux-android-ranlib i686-linux-android19-clang++ x86_64-linux-android22-clang aarch64-linux-android-readelf i686-linux-android21-clang x86_64-linux-android22-clang++ aarch64-linux-android-size i686-linux-android21-clang++ x86_64-linux-android23-clang aarch64-linux-android-strings i686-linux-android22-clang x86_64-linux-android23-clang++ aarch64-linux-android-strip i686-linux-android22-clang++ x86_64-linux-android24-clang arm-linux-androideabi-addr2line i686-linux-android23-clang x86_64-linux-android24-clang++ arm-linux-androideabi-ar i686-linux-android23-clang++ x86_64-linux-android26-clang arm-linux-androideabi-as i686-linux-android24-clang x86_64-linux-android26-clang++ arm-linux-androideabi-c++filt i686-linux-android24-clang++ x86_64-linux-android27-clang arm-linux-androideabi-dwp i686-linux-android26-clang x86_64-linux-android27-clang++ arm-linux-androideabi-elfedit i686-linux-android26-clang++ x86_64-linux-android28-clang arm-linux-androideabi-gprof i686-linux-android27-clang x86_64-linux-android28-clang++ arm-linux-androideabi-ld i686-linux-android27-clang++ x86_64-linux-android29-clang arm-linux-androideabi-ld.bfd i686-linux-android28-clang x86_64-linux-android29-clang++ arm-linux-androideabi-ld.gold i686-linux-android28-clang++ x86_64-linux-android-addr2line arm-linux-androideabi-nm i686-linux-android29-clang x86_64-linux-android-ar arm-linux-androideabi-objcopy i686-linux-android29-clang++ x86_64-linux-android-as arm-linux-androideabi-objdump i686-linux-android-addr2line x86_64-linux-android-c++filt arm-linux-androideabi-ranlib i686-linux-android-ar x86_64-linux-android-dwp arm-linux-androideabi-readelf i686-linux-android-as x86_64-linux-android-elfedit arm-linux-androideabi-size i686-linux-android-c++filt x86_64-linux-android-gprof arm-linux-androideabi-strings i686-linux-android-dwp x86_64-linux-android-ld arm-linux-androideabi-strip i686-linux-android-elfedit x86_64-linux-android-ld.bfd armv7a-linux-androideabi16-clang i686-linux-android-gprof x86_64-linux-android-ld.gold armv7a-linux-androideabi16-clang++ i686-linux-android-ld x86_64-linux-android-nm armv7a-linux-androideabi17-clang i686-linux-android-ld.bfd x86_64-linux-android-objcopy armv7a-linux-androideabi17-clang++ i686-linux-android-ld.gold x86_64-linux-android-objdump armv7a-linux-androideabi18-clang i686-linux-android-nm x86_64-linux-android-ranlib armv7a-linux-androideabi18-clang++ i686-linux-android-objcopy x86_64-linux-android-readelf armv7a-linux-androideabi19-clang i686-linux-android-objdump x86_64-linux-android-size armv7a-linux-androideabi19-clang++ i686-linux-android-ranlib x86_64-linux-android-strings armv7a-linux-androideabi21-clang i686-linux-android-readelf x86_64-linux-android-strip armv7a-linux-androideabi21-clang++ i686-linux-android-size yasm armv7a-linux-androideabi22-clang i686-linux-android-strings armv7a-linux-androideabi22-clang++ i686-linux-android-stripRust 交叉编译工具链选择
下面列出 Rust 支持的交叉编译平台:
$ rustc --print target-list | pr -tw100 --columns 3 aarch64-fuchsia i686-pc-windows-msvc sparc-unknown-linux-gnu aarch64-linux-android i686-unknown-cloudabi sparc64-unknown-linux-gnu aarch64-pc-windows-msvc i686-unknown-freebsd sparc64-unknown-netbsd aarch64-unknown-cloudabi i686-unknown-haiku sparc64-unknown-openbsd aarch64-unknown-freebsd i686-unknown-linux-gnu sparcv9-sun-solaris aarch64-unknown-hermit i686-unknown-linux-musl thumbv6m-none-eabi aarch64-unknown-linux-gnu i686-unknown-netbsd thumbv7a-pc-windows-msvc aarch64-unknown-linux-musl i686-unknown-openbsd thumbv7em-none-eabi aarch64-unknown-netbsd i686-unknown-uefi thumbv7em-none-eabihf aarch64-unknown-none i686-uwp-windows-gnu thumbv7m-none-eabi aarch64-unknown-none-softfloat i686-uwp-windows-msvc thumbv7neon-linux-androideabi aarch64-unknown-openbsd i686-wrs-vxworks thumbv7neon-unknown-linux-gnueab aarch64-unknown-redox mips-unknown-linux-gnu thumbv7neon-unknown-linux-muslea aarch64-uwp-windows-msvc mips-unknown-linux-musl thumbv8m.base-none-eabi aarch64-wrs-vxworks mips-unknown-linux-uclibc thumbv8m.main-none-eabi arm-linux-androideabi mips64-unknown-linux-gnuabi64 thumbv8m.main-none-eabihf arm-unknown-linux-gnueabi mips64-unknown-linux-muslabi64 wasm32-unknown-emscripten arm-unknown-linux-gnueabihf mips64el-unknown-linux-gnuabi64 wasm32-unknown-unknown arm-unknown-linux-musleabi mips64el-unknown-linux-muslabi64 wasm32-wasi arm-unknown-linux-musleabihf mipsel-unknown-linux-gnu x86_64-apple-darwin armebv7r-none-eabi mipsel-unknown-linux-musl x86_64-fortanix-unknown-sgx armebv7r-none-eabihf mipsel-unknown-linux-uclibc x86_64-fuchsia armv4t-unknown-linux-gnueabi mipsisa32r6-unknown-linux-gnu x86_64-linux-android armv5te-unknown-linux-gnueabi mipsisa32r6el-unknown-linux-gnu x86_64-linux-kernel armv5te-unknown-linux-musleabi mipsisa64r6-unknown-linux-gnuabi x86_64-pc-solaris armv6-unknown-freebsd mipsisa64r6el-unknown-linux-gnua x86_64-pc-windows-gnu armv6-unknown-netbsd-eabihf msp430-none-elf x86_64-pc-windows-msvc armv7-linux-androideabi nvptx64-nvidia-cuda x86_64-rumprun-netbsd armv7-unknown-cloudabi-eabihf powerpc-unknown-linux-gnu x86_64-sun-solaris armv7-unknown-freebsd powerpc-unknown-linux-gnuspe x86_64-unknown-cloudabi armv7-unknown-linux-gnueabi powerpc-unknown-linux-musl x86_64-unknown-dragonfly armv7-unknown-linux-gnueabihf powerpc-unknown-netbsd x86_64-unknown-freebsd armv7-unknown-linux-musleabi powerpc-wrs-vxworks x86_64-unknown-haiku armv7-unknown-linux-musleabihf powerpc-wrs-vxworks-spe x86_64-unknown-hermit armv7-unknown-netbsd-eabihf powerpc64-unknown-freebsd x86_64-unknown-hermit-kernel armv7-wrs-vxworks-eabihf powerpc64-unknown-linux-gnu x86_64-unknown-illumos armv7a-none-eabi powerpc64-unknown-linux-musl x86_64-unknown-l4re-uclibc armv7a-none-eabihf powerpc64-wrs-vxworks x86_64-unknown-linux-gnu armv7r-none-eabi powerpc64le-unknown-linux-gnu x86_64-unknown-linux-gnux32 armv7r-none-eabihf powerpc64le-unknown-linux-musl x86_64-unknown-linux-musl asmjs-unknown-emscripten riscv32i-unknown-none-elf x86_64-unknown-netbsd hexagon-unknown-linux-musl riscv32imac-unknown-none-elf x86_64-unknown-openbsd i586-pc-windows-msvc riscv32imc-unknown-none-elf x86_64-unknown-redox i586-unknown-linux-gnu riscv64gc-unknown-linux-gnu x86_64-unknown-uefi i586-unknown-linux-musl riscv64gc-unknown-none-elf x86_64-uwp-windows-gnu i686-apple-darwin riscv64imac-unknown-none-elf x86_64-uwp-windows-msvc i686-linux-android s390x-unknown-linux-gnu x86_64-wrs-vxworks i686-pc-windows-gnu我们可以直接搜索和 android 相关的:
$ rustc --print target-list | grep android aarch64-linux-android arm-linux-androideabi armv7-linux-androideabi i686-linux-android thumbv7neon-linux-androideabi x86_64-linux-android- aarch64 是 64 位的 ARM CPU 架构。
- arm 是 32 位的 ARM CPU 架构。
- armv7 是 32 位的 ARM CPU 架构。
- i686 是 32 位的 x86 CPU 架构。
- x86_64 是 64 位的 x86 CPU 架构。
- thumbv7neon 不认识。
很明显我们就是选择第一个
aarch64-linux-android。然后我们需要安装下这个平台的开发环境:
rustup target add aarch64-linux-android安装好之后在
~/.cargo/config文件里面添加如下内容:[target.aarch64-linux-android] linker = "/home/huangjian/android-ndk-r21b/toolchains/llvm/prebuilt/linux-x86_64/bin/aarch64-linux-android29-clang"这里的 linker 填写的就是我们前面下载的 android 交叉编译工具目录下的编译器路径。
编译命令如下:
cargo build --target=aarch64-linux-android资源链接
- https://developer.android.com/ndk
- https://developer.android.com/ndk/guides/other_build_systems
- https://github.com/japaric/rust-cross
-
[Network] can、isotp 和 isotptun
背景介绍
CAN 是控制器局域网络(Controller Area Network, CAN)的简称,是由以研发和生产汽车电子产品著称的德国 BOSCH 公司开发的,并最终成为国际标准(ISO 11898),是国际上应用最广泛的现场总线之一。CAN 传输协议提供点对点的通信,在两个 CAN 节点之间通过
CAN ID来进行通信。如下图所示: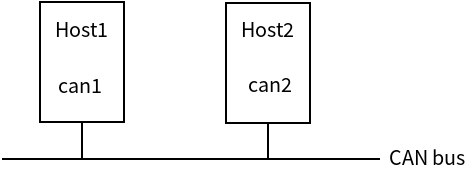
ISO-TP 协议是一个基于 CAN 协议的请求应答协议。ISO-TP 协议是一个不可靠的数据报协议。因此,不支持错误提示,例如:“由于错误的序列号导致了数据包丢失”是没有任何提示的。ISO-TP 协议示意图如下:
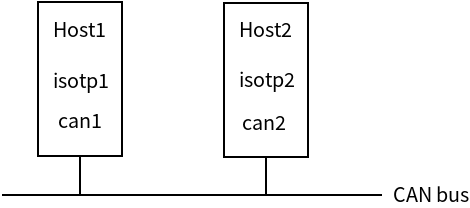
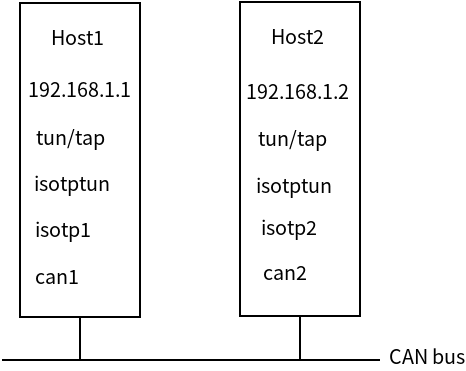
isotptun 是基于 ISO-TP 协议的双向 IP 隧道。示意图如下:
CAN 协议介绍
在 Linux 下的
/usr/include/linux/can.h文件下,可以看到定义的 CAN 帧的结构体:struct can_frame { u32 can_id; u8 can_dlc; u8 __pad; /* padding */ u8 __res0; /* reserved / padding */ u8 __res1; /* reserved / padding */ u8 data[8]; };- can_id:是 CAN 帧的标识符。
- can_dlc:是这个 CAN 帧数据的长度,就是 data 字段中保存了几个字节的数据。
- data:就是这个 CAN 帧携带的数据,最多只能携带 8 个字节。
- 其他:其他 3 个字段目前没有用到。
通过上面的结构体,我们可以看到 CAN 帧的结构体非常简单,可以携带的数据量也是少的惊人,只有 8 个字节。 而我们却要在这 8 个字节上面实现一个请求应答协议,真是难以想象。像 TCP 这种复杂的请求应答协议,单单一个头部都至少有 20 个字节的长度。
ISO-TP 协议介绍
ISO-TP 协议 就是在 CAN 协议上面实现的请求应答协议,ISO-TP 协议用一个字节来作为头部,剩下的用来传输数据。ISO-TP 协议一共定义了 4 种帧的类型。
- Single Frame:
单帧,发送的数据在一个 CAN 帧里面就可以放得下的时候,可以直接使用单帧。 - First Frame:
首帧,发送的数据在一个 CAN 帧里面放不下,需要拆分为多个 CAN 帧时,先发送一个首帧。 - Consecutive Frame:
连续帧,在发送完首帧之后,发送连续帧。 - Flow Control:
流控帧,在收到对方的首帧之后,回应一个流控帧,对方在收到流控帧之后才能发送连续帧。
因为 ISO-TP 协议是基于 CAN 协议的,所以一共就只有 8 个字节可以使用,ISO-TP 协议是使用第一个字节的前面 4 个比特来表示帧的类型。如下图所示:
PCI function nibble bit value SF Single Frame 0 0000xxxx FF First Frame 1 0001xxxx CF Consecutive Frame 2 0010xxxx FC Flow Control 3 0011xxxx 因为每一个 CAN 帧都至少使用了一个字节来标识类型,所以基于 8 个字节的 CAN 协议的 ISO-TP 协议开销至少是
1/8 = 12.5%。有一种叫CAN FD的扩展 CAN 协议,可以携带高达 64 字节的数据,如果 ISO-TP 协议是基于CAN FD的话,那协议的开销就是1/64 = 1.6%。但是很可惜,windows 下的第三方驱动只支持 8 个字节的经典 CAN 协议。ISO-TP 协议发送数据流程图
ISO-TP 协议提供了分段、带流控的数据传输、重组这些功能。ISO-TP 协议的主要作用是能够传输大于单个 CAN 帧能够传输的数据。大于单个 CAN 帧的数据会被拆分为多个部分(分段),每个部分都能够通过单个 CAN 帧来传输,接收端对收到的数据进行重组。
下图展示了未被分段的数据传输。
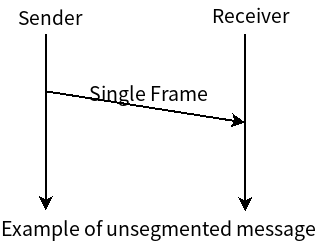
下图展示了分段的数据传输。
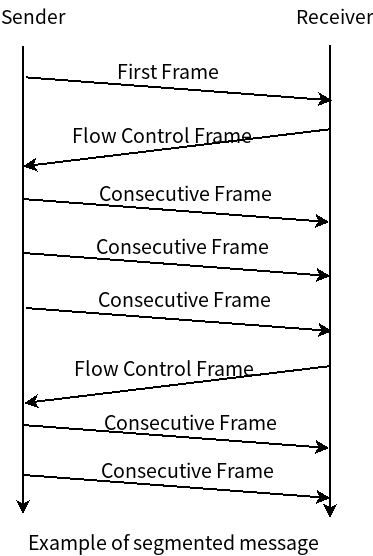
ISO-TP 协议帧详细设计
下面我们来看下 ISO-TP 协议 4 个帧的详细设计:
PCI B[0] B[1] B[2] B[3] B[4] B[5] B[6] B[7] SF 0000 LLLL data data data data data data data FF 0001 LLLL LLLLLLLL data data data data data data CF 0010 NNNN data data data data data data data FC 0011 FFFF Blocksize STm n.a. n.a. n.a. n.a. n.a. - LLLL:PDU(Protocol Data Unit) 的长度信息。
- NNNN:
连续帧中的序列号,一共只有 4 比特,所以数据范围是0 ~ 15。 - FFFF:流控状态信息。
- Blocksize:
0 ~ 15(0 = disabled) - STm:Separation Time minimum,最小发送间隔。
- data:PDU payload data,上层要发送的数据。
- n.a.:未分配。
- B[x]:CAN 帧中的第 x 个字节。
Single Frame(SF)
SF 的帧标识是第一个字节的前面 4 个比特,是 0。
SF 的第一个字节后面 4 个比特表示的是帧的数据长度,最大可以表示
2^4 - 1 = 15字节。一个 CAN 帧才 8 个字节,首部用去了一个字节,所以 SF 最多只能发送 7 个字节的数据。First Frame(FF)
FF 的帧标识是第一个字节的前面 4 个比特,是 1。
FF 是用第一个字节的后面 4 个比特和第二个字节合起来表示整个 PDU 的数据长度,最大可以表示
2^12 - 1 = 4095字节。这说明了 ISO-TP 协议 给上层提供的接口中,最大能够发送的数据长度就是 4095,如果超过了这个长度,上层就需要自己来分段。不过 ISO-TP 协议 这里提供了一种增强版的实现。把表示数据长度的这 12 比特全部置为 0,然后用接下来的 4 个字节来表示整个 PDU 的数据长度,最大可以表示
2^32 - 1 字节(~4GB)。Consecutive Frame(CF)
CF 的帧标识是第一个字节的前面 4 个比特,是 2。
CF 的第一个字节的后面 4 个比特,表示的是序列号,范围是
0 ~ 15,从 0 开始一直增加到 15,然后再次从 0 开始。CF 没有表示数据长度的字段的,除了第一个字节之外,剩下的都是数据。只有最后一个 CF 的数据才可能没有填充满。
Flow Control Frame(FC)
FC 的帧标识是第一个字节的前面 4 个比特,是 3。
ISO-TP 协议对丢包的处理
CAN 协议本身存在丢包的可能,在测试的过程中,如果大量发送 CAN 帧,丢包几乎就是必现的情况。所以 ISO-TP 协议里面加入了序列号来处理丢包的情况。
在
连续帧中,第一个字节的后面 4 个比特,就是表示序列号,范围是0 ~ 15,当序列号达到 15 之后就又从 0 开始。在接收端会检查这个序列号是否正确,如果发现错误了,接收端会把之前已经读取到的数据清空,并等待下一个首帧的到来。也就是说接下来收到的所有连续帧都会被丢弃。总结:一个 PDU 可以被拆分为多个 CAN 帧,一旦出现 CAN 帧丢失,整个 PDU 就会被丢弃。
isotptun 介绍
isotptun 是基于 ISO-TP 协议的双向 IP 隧道。isotptun 启用之后,两个端点之间就可以直接通过 IP 来通信了。那这是怎么实现的呢?
假定我们有如下模块:
host1,虚拟网卡1,isotptun1,isotp模块1,can模块1host2,虚拟网卡2,isotptun2,isotp模块2,can模块2
一共涉及两台主机
host1和host2。isotptun1在host1上面创建虚拟网卡1。isotptun2在host2上面创建虚拟网卡2。isotptun1把从虚拟网卡1读取到的数据写入isotp模块1。isotptun1把从isotp模块1读取到的数据写入虚拟网卡1。isotptun2把从虚拟网卡2读取到的数据写入isotp模块2。isotptun2把从isotp模块2读取到的数据写入虚拟网卡2。isotp模块1和isotp模块2的数据最终会通过can模块1和can模块2进入CAN bus总线。通过CAN ID来找到对方。虚拟网卡创建之后,可以给
虚拟网卡1分配一个 IP 地址192.168.1.1,给虚拟网卡2分配一个 IP 地址192.168.1.2。当然,你也可以分配其他的 IP 地址,只要两个主机是在同一个网段内就可以。这样,两个主机就像是在同一个局域网内。缺陷:
- 由于 CAN 协议本身速度较慢,所以在测试时,速度一般也就只能达到十几 KBytes/s。
- CAN 协议这里存在丢包的可能,所以一旦丢包,会导致 TCP 大量重传。
问题:上面说 ISO-TP 协议会丢包,那为什么可以用来建立 IP 隧道?
答:只要上层使用基于 TCP 的协议,TCP 本身会重传,所以没有问题。ISO-TP 协议 可以认为是一个类似于数据链路层的协议。那如果你用的是 UDP 协议的话,那数据就是有可能出现丢失。
相关资源
- ISO 15765-2.pdf
- hartkopp/can-isotp
- linux-can/can-utils
-
[Network] 协程
ucontext
ucontext 提供了 4 个函数,ubuntu 系统上头文件在
/usr/include/ucontext.h。/* Get user context and store it in variable pointed to by UCP. */ extern int getcontext (ucontext_t *__ucp) __THROWNL; /* Set user context from information of variable pointed to by UCP. */ extern int setcontext (const ucontext_t *__ucp) __THROWNL; /* Save current context in context variable pointed to by OUCP and set context from variable pointed to by UCP. */ extern int swapcontext (ucontext_t *__restrict __oucp, const ucontext_t *__restrict __ucp) __THROWNL; /* Manipulate user context UCP to continue with calling functions FUNC and the ARGC-1 parameters following ARGC when the context is used the next time in `setcontext' or `swapcontext'. We cannot say anything about the parameters FUNC takes; `void' is as good as any other choice. */ extern void makecontext (ucontext_t *__ucp, void (*__func) (void), int __argc, ...) __THROW;可以使用
man getcontext、man setcontext、man swapcontext、man makecontext来 查看详细帮助文档。相关资源
-
[算法学习][leetcode] 70. 爬楼梯
https://leetcode-cn.com/problems/climbing-stairs/
参考答案 – 递归
时间复杂度为 O(2^n),会超时。
class Solution: def climbStairs(self, n: int) -> int: if n < 3: return n return self.climbStairs(n - 1) + self.climbStairs(n - 2)参考答案 – 递归加缓存
时间复杂度为 O(n)。
class Solution: def climbStairs(self, n: int) -> int: return self.recursion(n, {}) def recursion(self, n, m): if n < 3: return n if n in m: return m[n] m[n] = self.recursion(n - 1, m) + self.recursion(n - 2, m) return m[n]参考答案 – 递推
时间复杂度为 O(n)。
Python 代码
class Solution: def climbStairs(self, n: int) -> int: if n < 3: return n f1, f2 = 1, 2 for i in range(2, n): f1, f2 = f2, f1 + f2 return f2JavaScript 代码
/** * @param {number} n * @return {number} */ var climbStairs = function(n) { if (n < 3) { return n; } let f1 = 1; let f2 = 2; for (let i = 3; i <= n; i += 1) { [f1, f2] = [f2, f1 + f2]; } return f2; };Rust 代码
impl Solution { pub fn climb_stairs(n: i32) -> i32 { if n < 3 { return n; } let mut f1 = 1; let mut f2 = 2; for _ in 2..n { let next = f1 + f2; f1 = f2; f2 = next; } return f2; } }Golang 代码
func climbStairs(n int) int { if n < 3 { return n } f1, f2 := 1, 2 for i := 3; i <= n; i++ { f1, f2 = f2, f1+f2 } return f2 }C++ 代码
class Solution { public: int climbStairs(int n) { if (n < 3) { return n; } int f1 = 1; int f2 = 2; for (int i = 2; i < n; i++) { int next = f1 + f2; f1 = f2; f2 = next; } return f2; } };
-
[算法学习][leetcode] 283. 移动零
https://leetcode-cn.com/problems/move-zeroes/
参考答案
Python 代码
class Solution: def moveZeroes(self, nums: List[int]) -> None: """ Do not return anything, modify nums in-place instead. """ j = 0 for i in range(len(nums)): if nums[i] != 0: nums[i], nums[j] = nums[j], nums[i] j += 1JavaScript 代码
/** * @param {number[]} nums * @return {void} Do not return anything, modify nums in-place instead. */ var moveZeroes = function(nums) { let j = 0; for (let i = 0; i < nums.length; i += 1) { if (nums[i] !== 0) { [nums[i], nums[j]] = [nums[j], nums[i]]; j += 1; } } };Rust 代码
impl Solution { pub fn move_zeroes(nums: &mut Vec<i32>) { let mut j = 0; for i in 0..nums.len() { if nums[i] != 0 { if j != i { nums.swap(i, j); } j += 1; } } } }Golang 代码
func moveZeroes(nums []int) { j := 0 for i := range nums { if nums[i] != 0 { nums[i], nums[j] = nums[j], nums[i] j++ } } }C++ 代码
class Solution { public: void moveZeroes(vector<int>& nums) { int j = 0; int n = nums.size(); for (int i = 0; i < n; i++) { if (nums[i] != 0) { swap(nums[i], nums[j++]); } } } };
-
[算法学习][leetcode] 11. 盛最多水的容器
https://leetcode-cn.com/problems/container-with-most-water/
参考题解,暴力法
直接两重循环,遍历左右两根柱子的所有组合情况。因为两重循环,所以时间复杂度为 O(n^2)。 因为没有而外开辟空间,所以空间复杂度为 O(1)。
Python 的代码会超出时间限制,Rust 和 Golang 这种需要编译的代码可以过,不过速度比较慢。
Python 代码
class Solution: def maxArea(self, height: List[int]) -> int: result = 0 for i in range(len(height)-1): for j in range(i + 1, len(height)): curHeight = min(height[i], height[j]) curWdith = j - i curArea = curWdith * curHeight result = max(result, curArea) return resultJavaScript 代码
/** * @param {number[]} height * @return {number} */ var maxArea = function(height) { let result = 0; for (let i = 0; i < height.length; i += 1) { for (let j = i + 1; j < height.length; j += 1) { const curWidth = j - i; const curHeight = Math.min(height[i], height[j]); const curArea = curWidth * curHeight; if (curArea > result) { result = curArea; } } } return result; };Rust 代码
impl Solution { pub fn max_area(height: Vec<i32>) -> i32 { let mut result = i32::min_value(); for i in 0..(height.len() - 1) { for j in (i + 1)..(height.len()) { result = i32::max(result, i32::min(height[i], height[j]) * (j - i) as i32); } } result } }Golang 代码
func maxArea(height []int) int { result := 0 for i := 0; i < len(height)-1; i++ { for j := i + 1; j < len(height); j++ { curArea := 0 if height[i] < height[j] { curArea = height[i] * (j - i) } else { curArea = height[j] * (j - i) } if curArea > result { result = curArea } } } return result }C++ 代码
class Solution { public: int maxArea(vector<int>& height) { int result = 0; for (int i = 0; i < height.size() - 1; i++) { for (int j = 0; j < height.size(); j++) { int curHeight = min(height[i], height[j]); int curWidth = j - i; int curArea = curHeight * curWidth; result = max(result, curArea); } } return result; } };参考题解,双指针两头夹逼
这方法不是很好理解,建议先看看代码,再回来看分析。
我这里提供一个思路:我们把数组最左边的柱子叫做 a,最右边的柱子叫做 b。 假设 a 的高度小于 b。同时在 a 和 b 之间存在着一根柱子 c。
- 情况1:c <= a。这种情况 a 和 c 构成的面积一定小于 a 和 b 构成的面积。
- 情况2:a < c <= b。这种情况 a 和 c 构成的面积也一定小于 a 和 b 构成的面积。
- 情况3:b < c。这种情况 a 和 c 构成的面积还是一定小于 a 和 b 构成的面积。
上面 3 种情况,大家自己画个图就清楚了。 你会发现无论 c 是多高的。a 和 c 的面积都不可能超过 a 和 b 的面积, 也就是说柱子 a 和 ab 之间的任意一根柱子都没有必要判断了。
Python 代码
class Solution: def maxArea(self, height: List[int]) -> int: result, left, right = 0, 0, len(height)-1 while left < right: curHeight = min(height[left], height[right]) curWdith = right - left curArea = curWdith * curHeight result = max(result, curArea) if height[left] < height[right]: left += 1 else: right -= 1 return resultJavaScript 代码
/** * @param {number[]} height * @return {number} */ var maxArea = function(height) { let result = 0; let left = 0; let right = height.length - 1; while (left < right) { let curWidth = right - left; let curHeight = Math.min(height[left], height[right]); let curArea = curWidth * curHeight; if (curArea > result) { result = curArea; } if (height[left] < height[right]) { left += 1; } else { right -= 1; } } return result; };Rust 代码
impl Solution { pub fn max_area(height: Vec<i32>) -> i32 { let mut left = 0; let mut right = height.len() - 1; let mut result = 0; while left < right { let cur_height = std::cmp::min(height[left], height[right]); let cur_width = (right - left) as i32; let cur_area = cur_height * cur_width; result = std::cmp::max(result, cur_area); if height[left] < height[right] { left += 1; } else { right -= 1; } } result } }Golang 代码
func maxArea(height []int) int { result := 0 left := 0 right := len(height) - 1 for left < right { curArea := 0 if height[left] < height[right] { curArea = height[left] * (right - left) left++ } else { curArea = height[right] * (right - left) right-- } if curArea > result { result = curArea } } return result }C++ 代码
class Solution { public: int maxArea(vector<int>& height) { int result = 0; int left = 0; int right = height.size() - 1; while (left < right) { int curHeight = min(height[left], height[right]); int curWidth = right - left; int curArea = curHeight * curWidth; result = max(result, curArea); if (height[left] < height[right]) { left += 1; } else { right -= 1; } } return result; } };
- Jekyll 1
- C/C++ 63
- Linux 59
- Web 25
- Qt 12
- Art 124
- Windows 17
- PHP 8
- Network 16
- GDB 3
- lwip 2
- DesignPattern 6
- pthread 6
- CPrimerPlus 9
- tester 3
- GO 75
- openssl 7
- FreeRTOS 9
- 数据库 4
- vk_mj 7
- transdata 3
- Git 7
- lua 20
- nginx 19
- boost 9
- python 18
- google 1
- Redis 1
- miscellanea 11
- life 2
- GCTT 9
- Rust 15
- C语言 2
- TeX 3
- fp 1