Welcome to MDGSF's Blog!
This is my github blog-
[Network] 常用tcp代码
tcpunit.h
#ifndef TCP_UNIT_WIN_HJ #define TCP_UNIT_WIN_HJ #ifdef WIN32 #pragma comment(lib, "iphlpapi.lib") #pragma comment(lib, "ws2_32.lib") #include <WinSock2.h> #include <ws2tcpip.h> #include <MSTcpIP.h> #include <iphlpapi.h> #else #include <unistd.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <errno.h> #include <sys/ioctl.h> #include <sys/socket.h> #include <sys/types.h> #include <sys/ioctl.h> #include <sys/wait.h> #include <sys/epoll.h> #include <sys/stat.h> #include <arpa/inet.h> #include <netinet/in.h> #include <netinet/tcp.h> #include <net/if.h> #include <features.h> #include <fcntl.h> #endif #include "common_def.h" #include "utility.h" /* * @return * EXIT_SUCCESS: success. * EXIT_FAILURE: failed. * TCP_TIMEOUT: read or write timeout. * TCP_EOF: peer close the connection. */ void tcp_SetNonblock(int iSocket); void tcp_Setblock(int iSocket); void tcp_vCloseSocket(int & riSocket); /* * @param piSocket[out]: if success, return socket descriptor. * @param pcAddr[in]: ip address. * @param usPort[in]: ip port. * @param iTimeout[in]: Millisecond. */ int tcp_iConnect(int * piSocket, const char * pcAddr, unsigned short usPort, int iTimeout); /* * @param iSocket[in]: socket descriptor. * @param pcBuf[out]: buffer used to recv data. * @param piBufLen[in|out]: input the length of pcBuf, output the recvd length. */ int tcp_iRecvMsg(int iSocket, char * pcBuf, int * piBufLen); /* * @param iSocket[in]: socket descriptor. * @param pcBuf[out]: buffer used to recv data. * @param piBufLen[in|out]: * input the size of data want to read. * if return EXIT_SUCCESS, it means read success, * if return TCP_TIMEOUT, piBufLen output the size had already read. * @param iTimeout[in]: Millisecond. */ int tcp_iRecvMsgTimeout(int iSocket, char * pcBuf, int * piBufLen, int iTimeout); /* * @param iSocket[in]: socket descriptor. * @param pcBuf[in]: * @param piBufLen[in|out]: input the size of data ready to send, output the really size of data send success. */ int tcp_iSendMsg(int iSocket, const char * pcBuf, int * piBufLen); /* * @param iSocket[in]: socket descriptor. * @param pcBuf[in]: * @param iBufLen[in]: the size of data ready to send. */ int tcp_iSendAllMsg(int iSocket, const char * pcBuf, int iBufLen); /* * @param iSocket[in]: socket descriptor. * @param pcBuf[in]: * @param iSize[in]: the size of data ready to send. * @param iTimeout[in]: Millisecond. if your input <=0, it default use 100 milliseconds. */ int tcp_iSendMsgTimeout(int iSocket, const char * pcBuf, int iSize, int iTimeout); #endif
tcpunit_win.cpp
```cpp #include “tcpunit.h” #ifdef WIN32
void tcp_SetNonblock(int iSocket) { unsigned long flags = 1; ioctlsocket(iSocket, FIONBIO, &flags); }
void tcp_Setblock(int iSocket) { unsigned long flags = 0; ioctlsocket(iSocket, FIONBIO, &flags); }
void tcp_vCloseSocket(int & riSocket) { if(riSocket != 0) { closesocket(riSocket); riSocket = 0; } }
int tcp_iConnect(int *piSocket, const char * pcAddr, unsigned short usPort, int iTimeout) { int iRet;
if(NULL == piSocket || NULL == pcAddr || 0 == usPort) { printf("tcp_iConnect input error!\n"); return EXIT_FAILURE; } int iSocket = socket(AF_INET, SOCK_STREAM, 0); if(iSocket < 0) { printf("tcp_iConnect socket error!\n"); return EXIT_FAILURE; } int iTime = 2; setsockopt(iSocket, SOL_SOCKET, SO_RCVTIMEO, (char*)&iTime, sizeof(int)); int iKeepAlive = 1; //开启keepalive属性 int iKeepIdle = 120; //如果连接在120秒内没有任何数据往来,则进行探测 int iKeepInterval = 5; //探测发包的时间间隔为5秒 //int iKeepCount = 3; //探测尝试的次数 iRet = setsockopt(iSocket, SOL_SOCKET, SO_KEEPALIVE, (char*)&iKeepAlive, sizeof(iKeepAlive)); if(iRet != 0) { printf("tcp_iConnect SO_KEEPALIVE error=%d\n", WSAGetLastError()); } DWORD iByteNum; tcp_keepalive sPara = {1, iKeepIdle*1000, iKeepInterval*1000}; iRet = WSAIoctl(iSocket, SIO_KEEPALIVE_VALS, &sPara, sizeof(sPara), &sPara, sizeof(sPara), &iByteNum,NULL,NULL); if(iRet != 0) { printf("tcp_iConnect WSAIoctl SIO_KEEPALIVE_VALS error=%d\n", WSAGetLastError()); } tcp_SetNonblock(iSocket); struct sockaddr_in stAddr; memset(&stAddr, 0, sizeof(stAddr)); stAddr.sin_family = AF_INET; stAddr.sin_port = htons(usPort); stAddr.sin_addr.s_addr = inet_addr(pcAddr); memset(stAddr.sin_zero, 0x00, 8); iRet = ::connect(iSocket, (struct sockaddr*)&stAddr, sizeof(stAddr)); if(iRet < 0) { DWORD dwError = GetLastError(); if(dwError != WSAEINPROGRESS && dwError != WSAEWOULDBLOCK) { printf("tcp_iConnect connect error(%d)\n", GetLastError()); tcp_vCloseSocket(iSocket); return EXIT_FAILURE; } } else if(iRet == 0) { tcp_Setblock(iSocket); return EXIT_SUCCESS; } fd_set stReadSet; fd_set stWriteSet; FD_ZERO(&stReadSet); FD_SET(iSocket, &stReadSet); stWriteSet = stReadSet; struct timeval stTimeInterval; stTimeInterval.tv_sec = iTimeout / 1000; stTimeInterval.tv_usec = (iTimeout % 1000) * 1000; iRet = select(0, &stReadSet , &stWriteSet, NULL, &stTimeInterval); if(iRet <= 0) { printf("tcp_iConnect select iRet=%d\n", iRet); tcp_vCloseSocket(iSocket); return EXIT_FAILURE; }DONE: tcp_Setblock(iSocket);
*piSocket = iSocket; return EXIT_SUCCESS; }int tcp_iRecvMsg(int iSocket, char pcBuf, int * piBufLen) { if(iSocket <=0 || NULL == pcBuf || NULL == piBufLen || (piBufLen < 0)) { printf(“tcp_iRecvMsg input error!\n”); return EXIT_FAILURE; }
struct timeval stTimeInterval; stTimeInterval.tv_sec = 0; stTimeInterval.tv_usec = 100 * 1000; fd_set stReadSet; FD_ZERO(&stReadSet); FD_SET(iSocket, &stReadSet); int iActiveNum = select(iSocket + 1, &stReadSet, NULL, NULL, &stTimeInterval); if(iActiveNum == 1 && FD_ISSET(iSocket, &stReadSet)) { int iRecv = recv(iSocket, pcBuf , *piBufLen, 0); if(iRecv > 0) { *piBufLen = iRecv; return EXIT_SUCCESS; } else if(iRecv == 0) { return TCP_EOF; } } else if(iActiveNum == 0) { return TCP_TIMEOUT; } return EXIT_FAILURE; }int tcp_iRecvMsgTimeout(int iSocket, char * pcBuf, int * piBufLen, int iTimeout) { if(iSocket <=0 || NULL == pcBuf || NULL == piBufLen || (*piBufLen <= 0)) { printf(“tcp_iRecvMsgTimeout input error!\n”); return EXIT_FAILURE; }
struct timeval stTimeInterval; struct timeval stTimeIntervalTemp; stTimeInterval.tv_sec = 0; stTimeInterval.tv_usec = 10 * 1000; int iOnce = 0; int iRecv = 0; char *pcIndex = pcBuf; unsigned int uiCurrentTime = iclock(); unsigned int uiEndTime; if(iTimeout <= 0) uiEndTime = uiCurrentTime + 10 * 1000; else uiEndTime = uiCurrentTime + iTimeout * 1000; while ( (uiCurrentTime = iclock()) < uiEndTime ) { stTimeIntervalTemp = stTimeInterval; fd_set stReadSet; FD_ZERO(&stReadSet); FD_SET(iSocket, &stReadSet); iOnce = select(iSocket + 1, &stReadSet , NULL, NULL, &stTimeIntervalTemp); if(1 == iOnce && FD_ISSET(iSocket, &stReadSet)) { iOnce = recv(iSocket, pcIndex , *piBufLen - iRecv, 0); if(iOnce > 0) { iRecv += iOnce; if(iRecv >= *piBufLen) { return EXIT_SUCCESS; } else { pcIndex += iOnce; continue; } } else if(iOnce == 0) { return TCP_EOF; } } else if(iOnce == 0) { continue; } return EXIT_FAILURE; } *piBufLen = iRecv; return TCP_TIMEOUT; }int tcp_iSendMsg(int iSocket, const char pcBuf, int * piBufLen) { if(iSocket <= 0 || NULL == pcBuf || NULL == piBufLen || (piBufLen <= 0)) { printf(“tcp_iSendMsg input error!\n”); return EXIT_FAILURE; }
int iSendLen = send(iSocket, pcBuf, *piBufLen, 0); if(iSendLen < 0) { printf("tcp_iSendMsg send error. return value = %d. \n",iSendLen); return EXIT_FAILURE; } *piBufLen = iSendLen; return EXIT_SUCCESS; }int tcp_iSendAllMsg(int iSocket, const char *pcBuf, int iBufLen) { if(iSocket <= 0 || NULL == pcBuf || 0 == iBufLen) { printf(“tcp_iSendAllMsg input error!\n”); return EXIT_FAILURE; }
int iSendLen = 0; while(iSendLen < iBufLen) { int iSendLenTmp = send(iSocket, pcBuf + iSendLen, iBufLen - iSendLen, 0); if(iSendLenTmp < 0) { printf("tcp_iSendAllMsg send error. return value = %d. \n",iSendLenTmp); return EXIT_FAILURE; } iSendLen += iSendLenTmp; } return EXIT_SUCCESS; }int tcp_iSendMsgTimeout(int iSocket, const char *pcBuf, int iSize, int iTimeout) { if(iSocket <= 0 || NULL == pcBuf || iSize <= 0) { printf(“tcp_iSendMsgTimeout input error!\n”); return EXIT_FAILURE; }
int iTotalWriteLen = 0; char * pcBufferIndex = (char *)pcBuf; unsigned int uiCurrentTime = iclock(); unsigned int uiEndTime; if(iTimeout <= 0) uiEndTime = uiCurrentTime + 100 * 1000; else uiEndTime = uiCurrentTime + iTimeout * 1000; while((uiCurrentTime = iclock()) < uiEndTime) { struct timeval stTimeInterval; stTimeInterval.tv_sec = 0; stTimeInterval.tv_usec = 10 * 1000; fd_set stWriteSet; FD_ZERO(&stWriteSet); FD_SET(iSocket, &stWriteSet); int iOnce = select(iSocket + 1, NULL , &stWriteSet, NULL, &stTimeInterval); if(1 == iOnce && FD_ISSET(iSocket, &stWriteSet)) { int iWriteLen = send(iSocket, pcBufferIndex, iSize - iTotalWriteLen, 0); if(iWriteLen > 0) { iTotalWriteLen += iWriteLen; if(iTotalWriteLen >= iSize) { /** write completely */ return EXIT_SUCCESS; } else { pcBufferIndex += iWriteLen; continue; } } else { printf("tcp_iSendMsgTimeout send error\n"); return EXIT_FAILURE; } } else if(0 == iOnce) { continue; // select timeout } else { printf("tcp_iSendMsgTimeout select error\n"); return EXIT_FAILURE; } } return TCP_TIMEOUT; }
-
[Network][NTP] 网络时间同步技术
NTP
NTP(Network Time Protocol)从1985年诞生来,目前仍在在大部分的计算机网络中起着同步系统时间的作用。
基本原理
服务器和客户端之间通过二次报文交换,确定主从时间误差,客户端校准本地计算机时间,完成时间同步,有条件的话进一步校准本地时钟频率。
时间同步过程
服务器在UDP的132端口提供授时服务,客户端发送附带T1时间戳(Timestamp)的查询报文给服务器, 服务器在该报文上添加到达时刻T2和响应报文发送时刻T3,客户端记录响应报到达时刻T4。
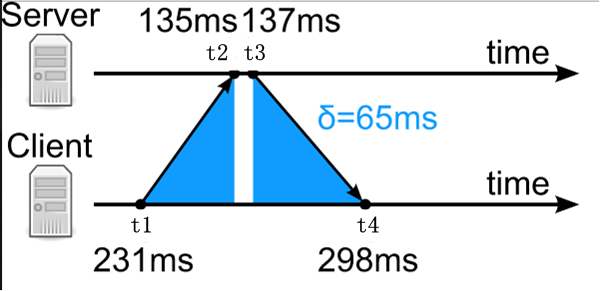
时差计算
这个图中用蓝色标注了主从直接来回链路的时延Sigma:
Sigma = (t4-t1)-(t3-t2)
因此,假设来回网络链路是对称的,即传输时延相等,那么可以计算客户端与服务器之间的时间误差Delta为:
Delta = t2-t1-Sigma/2=((t2-t1)+(t3-t4))/2
客户端调整自身的时间Delta,即可完成一次时间同步。
其实很好理解,你只要想一下,如果client和server的时间本来就是同步好的。 那么 t1 + Sigma/2 == t2,这个式子的意思是, 数据包从client发送时出发的时间,加上数据包在网络中传输到server的时间, 就应该等于数据包到达server时,server的时间。
t1 = 231 , t2 = 135 , t3 = 137 , t4 = 298 Sigma = (t4-t1) - (t3-t2) = 65 Delta = t2 - t1 - Sigma/2 = -128.5t4-t1 : 就是client从发出数据包一直到收到数据包的时间。
t3-t2 :就是server处理这个消息的时间。
Sigma : 即为数据包在网络中来回的时间。
Sigma/2 : 就是数据包从client到server的时间,或者说是从server到client的时间,这是一个平均值。
Delta : 就是client和server的时间差值。是个负数,说明client的时间快了。是正数,说明client时间慢了。等于零,说明client和server的时间已经是同步的了。
误差分析
局域网内计算机利用NTP协议进行时间同步,时间同步精度在5ms左右,主要误差包括:
1)计算机打时间戳的位置在应用层,受协议栈缓存、任务调度等影响,不能在网络报文到来时马上打戳;
2)各种中间网络传输设备带来的传输时延不确定性以及链路的不对称性,将进一步降低NTP时间同步精度。
参考链接
-
[C/C++] 和数组有关的一道题
给定一个数组a[N],我们希望构造数组b [N],其中b[j]=a[0]*a[1]…a[N-1] / a[j], 在构造过程中,不允许使用除法: 要求O(1)空间复杂度和O(n)的时间复杂度; 除遍历计数器与a[N] b[N]外,不可使用新的变量(包括栈临时变量、堆空间和全局静态变量等)
#include <stdio.h> void Translate(int a[], int b[], int n) { b[0] = 1; int i = 0; for (i = 1; i < n; i++) { b[i] = b[i-1] * a[i-1]; } for (i = n-1; i >= 1; i--) { b[i] *= b[0]; b[0] *= a[i]; } } int main() { int a[4] = {1, 2, 3, 4}; int b[4] = {0}; Translate(a, b, 4); for (int i = 0; i < 4; i++) { printf("%d ", b[i]); } printf("\n"); return 0; }一共循环2次,第一次从1到n-1,第二次从n-1到1.
第一次循环,对于第k个数,是计算 0~k-1 的乘积。
第二次循环,对于第k个数,是计算 k+1~n-1 的乘积。
-
[C/C++] strstr 不使用KMP达到O(n)的时间复杂度
问题
哈希表应用:字符串匹配 设字符串A="12314123" 求 "123" 在A中出现的次数 不会写KMP又要O(n)的时间复杂度。 Key( "123" ) = '1' * 10^2 + '2' * 10 + '3' = 123 HashMap = [123, 231, 314, 141, 412, 123] 但是这个时候为了求每个自串,时间复杂度还是O(n*m) 所以,这时候需要用到一个小技巧。 对字符串 "1234" 1 * 10^2 + 2 * 10 + 3 (式子A) 2 * 10^2 + 3 * 10 + 4 (式子B) A的后半部分和B的前半部分很像,去掉冗余, (A - 1*10^2) * 10 + 4 = B 这样计算子串就是O(1)的时间,总的时间复杂度就是O(n) 其实关键在于哈希函数,本来每个子串都要计算一次Key,现在利用了前一个子串的Key,降低了时间复杂度。代码
#include <stdio.h> #include <stdlib.h> #include <string.h> typedef struct _SNode { struct _SNode * next; char m_acSubStr[BUFSIZ]; int m_iNum; _SNode() { memset(m_acSubStr, 0, sizeof(m_acSubStr)); m_iNum = 0; next = NULL; } _SNode(const char * pcStr) { strncpy(m_acSubStr, pcStr, sizeof(m_acSubStr)); m_iNum = 1; next = NULL; } }SNode; typedef struct _SHashMap { int m_iHashMapCapacity; SNode * m_piHashMap; _SHashMap(int iHashMapCapacity, SNode * piHashMap) { m_iHashMapCapacity = iHashMapCapacity; m_piHashMap = piHashMap; } }SHashMap; SHashMap * hm_Init(int iHashMapCapacity) { SNode * piHashMap = (SNode*)malloc(sizeof(SNode) * iHashMapCapacity); SHashMap * pstHashMap = new SHashMap(iHashMapCapacity, piHashMap); return pstHashMap; } void hm_Insert(SHashMap * pstHashMap, int iKey, const char * pcStr) { //printf("hm_Insert() iKey = %d, pcStr = %s\n", iKey, pcStr); SNode * pHead = &(pstHashMap->m_piHashMap[iKey]); bool bFound = false; SNode * pCur = pHead; while (pCur->next != NULL) { pCur = pCur->next; if(strcmp(pCur->m_acSubStr, pcStr) == 0) { pCur->m_iNum++; bFound = true; } } if(!bFound) { SNode * pstNewNode = new SNode(pcStr); pCur->next = pstNewNode; } } SNode * hm_find(SHashMap * pstHashMap, int iKey, const char * pcStr) { SNode * pHead = &(pstHashMap->m_piHashMap[iKey]); SNode * pCur = pHead; while (pCur->next != NULL) { pCur = pCur->next; if(strcmp(pCur->m_acSubStr, pcStr) == 0) { return pCur; } } return NULL; } int iHashFunction(const char * pcStr, int iHashMapCapacity) { int iKey = 0; int iStrLen = strlen(pcStr); for (int i = 0; i < iStrLen; i++) { iKey = (iKey * 10 + pcStr[i]) % iHashMapCapacity; } return iKey; } int HashStrstr(const char * str1, const char * str2) { if(NULL == str1 || NULL == str2) { return 0; } int i = 0; int j = 0; int iKey = 0; int iPreKey = -1; int iRatio = 0; int iLen1 = strlen(str1); int iLen2 = strlen(str2); if(iLen1 <= 0 || iLen2 <= 0 || iLen1 < iLen2) { return 0; } //printf("[%s:%d], [%s:%d]\n", str1, iLen1, str2, iLen2); iRatio = 1; for (i = 0; i < iLen2 - 1; i++) { iRatio *= 10; } int iSubStrNum = iLen1 - iLen2 + 1; int iHashMapCapacity = iSubStrNum * 3; SHashMap * pstHashMap = hm_Init(iHashMapCapacity); //printf("iSubStrNum = %d, iHashMapCapacity = %d\n", iSubStrNum, iHashMapCapacity); for (i = 0; i < iSubStrNum; i++) { char acSubStr[BUFSIZ] = {0}; for (j = 0; j < iLen2; j++) { acSubStr[j] = str1[i+j]; } if(iPreKey == -1) { iKey = iHashFunction(acSubStr, iHashMapCapacity); } else { iKey = ((iPreKey - (str1[i-1]*iRatio)%iHashMapCapacity + iHashMapCapacity)*10 + acSubStr[iLen2-1])%iHashMapCapacity; } iPreKey = iKey; hm_Insert(pstHashMap, iKey, acSubStr); } iKey = iHashFunction(str2, iHashMapCapacity); SNode * pNode = hm_find(pstHashMap, iKey, str2); return pNode == NULL ? 0 : pNode->m_iNum; } void vTest(const char * pcCaseName, const char * pcStr1, const char * pcStr2, int iExpectResult) { int iRet = HashStrstr(pcStr1, pcStr2); if(iRet == iExpectResult) { printf("%s: pass\n", pcCaseName); } else { printf("%s: failed, iRet = %d\n", pcCaseName, iRet); } } void vTest1() { vTest("vTest1", "1234", "123", 1); } void vTest2() { vTest("vTest2", "1234123", "123", 2); } void vTest3() { vTest("vTest3", "1231231231123", "123", 4); } void vTest4() { vTest("vTest4", "1231231231123", "1", 5); } void vTest5() { vTest("vTest5", "abcd", "1", 0); } int main() { vTest1(); vTest2(); vTest3(); vTest4(); vTest5(); return 0; }
-
[C/C++] 复习题
11. 假设ClassY:publicX,即类Y是类X的派生类,则说明一个Y类的对象时和删除Y类对象时 ,调用构造函数和析构函数的次序分别为(A) A. X,Y;Y,X B. X,Y;X,Y C. Y,X;X,Y D. Y,X;Y,X15. 下列不能作为类的成员的是(B) A. 自身类对象的指针 B. 自身类对象 C. 自身类对象的引用 D. 另一个类的对象 答案:B 解析:类的定义,如果有自身类对象,使得循环定义,B项错误。在类中具有自身类的指针,可 以实现链表的操作,当然也可以使用对象的引用。类中可以有另一个类的对象,即成员对象。所 以选择B选项。17.下列程序的输出结果是() #include <iostream.h> void main() {int n[][3]={10,20,30,40,50,60}; int (*p)[3]; p=n; cout<<p[0][0]<<","<<*(p[0]+1)<<","<<(*p)[2]<<endl;} A. 10,30,50 B. 10,20,30 C. 20,40,60 D. 10,30,609. 对赋值运算符进行重载时,应声明为__类成员_函数。 答案:(P183)类成员 [解析]运算符重载的方法有友元或者成员函数两种途径,但是赋值运算符只能使用成员函数的 方法来实现。10. 如果要把A类成员函数f()且返回值为void声明为类B的友元函数,则应在类B的定义中加 入的语句_friend void A::f()__。 答案:(P109)friend void A::f(); [解析]成员函数作为另一个类的友元函数,格式为:friend 返回类型 类名::函数(形参)。14. 控制格式输入输出的操作中,函数___是用来设置填充字符。要求给出函数名和参数类型 答案:(P195)setfill(char) [解析]格式控制方法的使用,如setw,setfill等等。15. C++语言支持的两种多态性分别是编译时的多态性和__运行时_的多态性。 答案:(P167)运行时 [解析]多态性包括静态的(编译时)多态性和动态的(运行时)多态性。17. 执行下列代码 string str("HelloC++"); cout<<str.substr(5,3); 程序的输出结果是__C++_。 答案:(P42)C++ [解析]substr取子字符串,第1个参数表示要截取子串在字符串中的位置,第2个表示取多少个 字符。19. 定义类动态对象数组时,元素只能靠自动调用该类的_无参数构造函数__来进行初始化。 答案:(P77)无参构造函数 [解析]使用new 创建动态对象数组,不能有参数,所以只能调用无参的构造函数,初始化对象20. 已知有20个元素int类型向量V1,若用V1初始化为V2向量,语句是___。 答案:(P151)ector <int>V2(V1); [解析]采用向量初始化另一个向量的形式:vector <type> name1(name);3. #include <iostream.h> class A { int i; public: virtual void fun()=0; A(int a) {i=a;} }; class B:public A { int j; public: void fun() {cout<<"B::fun()\n"; } B(int m,int n=0):A(m),j(n){} }; void main() { A *pa; B b(7); pa=&b; } 答案:B(int m,int n=0):A(m),j(n){}因为基类是抽象类,不能被实例化,所以在派生类中不能 调用初始化基类对象。所以B(int m,int n=0):A(m),j(n){}错误,删去A(m)。 [修改]B(int m,int n=0):j(n){}1. 给出下面程序输出结果。 #include<iostream.h> class a {public: virtual void print() {cout<< "a prog..."<< endl;}; }; class b:public a {}; class c:public b {public: void print(){cout<<"c prog..."<<endl;} }; void show(a *p) {(*p).print(); } void main() {a a; b b; c c; show(&a);a prog… show(&b);a prog… show(&c);c prog } 答案:a prog... a prog... c prog... [解析]考查多态性的。a类对象调用本身的虚函数,b类因为没有覆写print,所以仍然调用基 类的虚函数。而c类重新定义print虚函数,所以调用c类的print。A * p = new A; A * p = new B; class A { void fun() {}; } clas B : public A { void fun() {}; } 有virtual, p->fun() 取决于右边 没有virtual, p->fun() 取决于左边
-
[C/C++] 二叉树的序列化和反序列化
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <iostream> #include <list> using namespace std; #define BT_SEP ',' #define EMPTY_NODE "#" typedef struct _STreeNode { int m_val; struct _STreeNode * left; struct _STreeNode * right; _STreeNode(int val) { m_val = val; left = NULL; right = NULL; } }SNode; char * _bt_Trim(char * pcStr) { if(NULL != pcStr) { for ( ; *pcStr && ::isspace(*pcStr); ++pcStr) ; char * pcLast = pcStr + strlen(pcStr) - 1; for ( ; pcLast >= pcStr && ::isspace(*pcLast); --pcLast) { *pcLast = 0; } } return pcStr; } SNode * bt_Init(const char * pcSerialize) { printf("bt_Init()\n"); if(NULL == pcSerialize || strlen(pcSerialize) <= 0) { return NULL; } SNode * root = NULL; list<SNode**> NodeList; NodeList.push_back(&root); int iSerializeLen = strlen(pcSerialize); char * pc = (char*)malloc(sizeof(char) * (iSerializeLen+1)); strncpy(pc, pcSerialize, iSerializeLen); char * pcStart = _bt_Trim(pc); char * pcEnd = strchr(pcStart, BT_SEP); while (1) { if(pcEnd != NULL) { *pcEnd = '\0'; } char acNode[BUFSIZ] = {0}; strcpy(acNode, _bt_Trim(pcStart)); if(strlen(acNode) <= 0) { NodeList.pop_front(); } else if(strcmp(acNode, EMPTY_NODE) == 0) { if(root == NULL) { return NULL; } else { NodeList.pop_front(); } } else { SNode * pNode = new SNode(atoi(acNode)); SNode ** ppParent = NodeList.front(); NodeList.pop_front(); NodeList.push_back(&pNode->left); NodeList.push_back(&pNode->right); *ppParent = pNode; } if(NULL == pcEnd) { break; } pcStart = pcEnd + 1; pcEnd = strchr(pcStart, BT_SEP); } return root; } void _bt_Show(list<SNode*> & NodeList) { SNode * pNode = NodeList.front(); if(pNode != NULL) { printf("%d,", pNode->m_val); NodeList.push_back(pNode->left); NodeList.push_back(pNode->right); if(pNode->left != NULL) { } if(pNode->right != NULL) { } } else { if(!NodeList.empty()) { printf("#,"); } } NodeList.pop_front(); if(!NodeList.empty()) { _bt_Show(NodeList); } } void bt_Show(SNode * root) { printf("bt_Show()\n"); list<SNode*> NodeList; NodeList.push_back(root); _bt_Show(NodeList); printf("\n"); } int main() { printf("Hello World!\n"); char ac[BUFSIZ] = {0}; strcpy(ac, "1,2,3,4,#,6,7,#,9,"); SNode * root = bt_Init(ac); if(NULL == root) { printf("bt_Init failed\n"); return -1; } bt_Show(root); return 0; }
- Jekyll 1
- C/C++ 63
- Linux 59
- Web 25
- Qt 12
- Art 124
- Windows 17
- PHP 8
- Network 16
- GDB 3
- lwip 2
- DesignPattern 6
- pthread 6
- CPrimerPlus 9
- tester 3
- GO 75
- openssl 7
- FreeRTOS 9
- 数据库 4
- vk_mj 7
- transdata 3
- Git 7
- lua 20
- nginx 19
- boost 9
- python 18
- google 1
- Redis 1
- miscellanea 11
- life 2
- GCTT 9
- Rust 15
- C语言 2
- TeX 3
- fp 1