Welcome to MDGSF's Blog!
This is my github blog-
[C/C++] GetAbsolutePath
问题描述 在操作系统中,数据通常以文件的形式存储在文件系统中。文件系统一般采用层次化的组织形式,由目录(或者文件夹)和文件构成,形成一棵树的形状。文件有内容,用于存储数据。目录是容器,可包含文件或其他目录。同一个目录下的所有文件和目录的名字各不相同,不同目录下可以有名字相同的文件或目录。 为了指定文件系统中的某个文件,需要用路径来定位。在类 Unix 系统(Linux、Max OS X、FreeBSD等)中,路径由若干部分构成,每个部分是一个目录或者文件的名字,相邻两个部分之间用 / 符号分隔。 有一个特殊的目录被称为根目录,是整个文件系统形成的这棵树的根节点,用一个单独的 / 符号表示。在操作系统中,有当前目录的概念,表示用户目前正在工作的目录。根据出发点可以把路径分为两类: Ÿ 绝对路径:以 / 符号开头,表示从根目录开始构建的路径。 Ÿ 相对路径:不以 / 符号开头,表示从当前目录开始构建的路径。 例如,有一个文件系统的结构如下图所示。在这个文件系统中,有根目录 / 和其他普通目录 d1、d2、d3、d4,以及文件 f1、f2、f3、f1、f4。其中,两个 f1 是同名文件,但在不同的目录下。 对于 d4 目录下的 f1 文件,可以用绝对路径 /d2/d4/f1 来指定。如果当前目录是 /d2/d3,这个文件也可以用相对路径 ../d4/f1 来指定,这里 .. 表示上一级目录(注意,根目录的上一级目录是它本身)。还有 . 表示本目录,例如 /d1/./f1 指定的就是 /d1/f1。注意,如果有多个连续的 / 出现,其效果等同于一个 /,例如 /d1///f1 指定的也是 /d1/f1。 本题会给出一些路径,要求对于每个路径,给出正规化以后的形式。一个路径经过正规化操作后,其指定的文件不变,但是会变成一个不包含 . 和 .. 的绝对路径,且不包含连续多个 / 符号。如果一个路径以 / 结尾,那么它代表的一定是一个目录,正规化操作要去掉结尾的 /。若这个路径代表根目录,则正规化操作的结果是 /。若路径为空字符串,则正规化操作的结果是当前目录。 输入格式 第一行包含一个整数 P,表示需要进行正规化操作的路径个数。 第二行包含一个字符串,表示当前目录。 以下 P 行,每行包含一个字符串,表示需要进行正规化操作的路径。 输出格式 共 P 行,每行一个字符串,表示经过正规化操作后的路径,顺序与输入对应。 样例输入 7 /d2/d3 /d2/d4/f1 ../d4/f1 /d1/./f1 /d1///f1 /d1/ /// /d1/../../d2 样例输出 /d2/d4/f1 /d2/d4/f1 /d1/f1 /d1/f1 /d1 / /d2 评测用例规模与约定 1 ≤ P ≤ 10。 文件和目录的名字只包含大小写字母、数字和小数点 .、减号 - 以及下划线 _。 不会有文件或目录的名字是 . 或 .. ,它们具有题目描述中给出的特殊含义。 输入的所有路径每个长度不超过 1000 个字符。 输入的当前目录保证是一个经过正规化操作后的路径。 对于前 30% 的测试用例,需要正规化的路径的组成部分不包含 . 和 .. 。 对于前 60% 的测试用例,需要正规化的路径都是绝对路径。#include <stdio.h> #include <stdlib.h> #include <string.h> #define PATHLEN 1024 /*** log ***/ //#define DEBUG #ifdef DEBUG #define LOG(format, ...) \ printf("<"__FILE__">(%05d): "format"", __LINE__, ##__VA_ARGS__) #else #define LOG(format, ...) #endif /*** log end ***/ /*** list ***/ typedef struct _SNode { struct _SNode * prev; struct _SNode * next; char m_acDir[PATHLEN]; }SNode; typedef struct _SList { struct _SNode * head; struct _SNode * tail; }SList; SNode * list_node_init(const char * pcDir) { SNode * pNode = (SNode*)malloc(sizeof(SNode)); pNode->prev = NULL; pNode->next = NULL; if(NULL == pcDir) { memset(pNode->m_acDir, 0, sizeof(pNode->m_acDir)); } else { strcpy(pNode->m_acDir, pcDir); } return pNode; } SList * list_init() { SList * pList = (SList*)malloc(sizeof(SList)); SNode * pHead = list_node_init(NULL); pList->head = pHead; pList->tail = pHead; return pList; } void list_insert_one_node(SNode * pNewNode, SNode * pPreNode, SNode * pCurNode) { pNewNode->prev = pPreNode; pNewNode->next = pCurNode; pPreNode->next = pNewNode; if(pCurNode != NULL) { pCurNode->prev = pNewNode; } } void list_delete_one_node(SNode * pNode) { if(NULL == pNode) { return ; } SNode * pPreNode = pNode->prev; SNode * pNextNode = pNode->next; pPreNode->next = pNextNode; if(pNextNode != NULL) { pNextNode->prev = pPreNode; } free(pNode); } void list_insert_node_tail(SList * pList, SNode * pNode) { list_insert_one_node(pNode, pList->tail, NULL); pList->tail = pNode; } void list_insert_tail(SList * pList, const char * pcData) { SNode * pNode = list_node_init(pcData); list_insert_node_tail(pList, pNode); } SList * list_join(SList * first, SList * second) { SList * pNewList = list_init(); pNewList->tail->next = first->head->next; first->head->next->prev = pNewList->tail; first->tail->next = second->head->next; second->head->next->prev = first->tail; first->head->next = NULL; first->tail = first->head; second->head->next = NULL; second->tail = second->head; return pNewList; } void list_destroy(SList * pList) { if(NULL == pList) { return ; } SNode * pCur = pList->head->next; while (pCur != NULL) { SNode * pNext = pCur->next; free(pCur); pCur = pNext; } free(pList); } void list_print(SList * pList) { #ifdef DEBUG SNode * pCur = pList->head->next; while (pCur != NULL) { printf("%s ", pCur->m_acDir); pCur = pCur->next; } printf("\n"); #endif } /*** list end ***/ SList * pstChangePathToList(const char * pcPath) { SList * pList = list_init(); char acPath[PATHLEN] = {0}; strcpy(acPath, pcPath); char * pStart = acPath; if(pStart[0] == '/') //absolute path { list_insert_tail(pList, "/"); pStart++; } while (*pStart != '\0') { char * pEnd = strchr(pStart, '/'); if(NULL == pEnd) //last one dir { list_insert_tail(pList, pStart); break; } else { if( pEnd == pStart ) //serial '/' { pStart++; } else { *pEnd = '\0'; list_insert_tail(pList, pStart); pStart = pEnd + 1; } } } list_print(pList); return pList; } void vTrimAbsolutePath(SList * pList, char * pcPath) { SNode * pCur = pList->head->next->next; if(NULL == pCur) { strcpy(pcPath, "/"); return ; } //delete '.' and '..' while (pCur != NULL) { if( strcmp(".", pCur->m_acDir) == 0 ) { SNode * pNext = pCur->next; list_delete_one_node(pCur); pCur = pNext; } else if( strcmp("..", pCur->m_acDir) == 0 ) { SNode * pNext = pCur->next; list_delete_one_node(pCur); pCur = pNext; if(pCur != NULL && pCur->prev != pList->head->next) { //if prev is root '/' list_delete_one_node(pCur->prev); } } else { pCur = pCur->next; } } pCur = pList->head->next->next; if(NULL == pCur) { strcpy(pcPath, "/"); return ; } while (pCur != NULL) { strcat(pcPath, "/"); strcat(pcPath, pCur->m_acDir); pCur = pCur->next; } } void vTrimRelativePath(SList * pCurList, SList * pSrcList, char * pcPath) { SList * pList = list_join(pCurList, pSrcList); vTrimAbsolutePath(pList, pcPath); list_destroy(pList); } void vGetAbsolutePath(const char * pcCurPath, const char * pcSrc, char * pcDst) { if(NULL == pcCurPath || NULL == pcSrc || NULL == pcDst) { return ; } LOG("pcCurPath: %s\n", pcCurPath); LOG("pcSrc: %s\n", pcSrc); SList * pCurList = pstChangePathToList(pcCurPath); SList * pSrcList = pstChangePathToList(pcSrc); if(pcSrc[0] == '/') //absolute path { vTrimAbsolutePath(pSrcList, pcDst); } else //relative path { vTrimRelativePath(pCurList, pSrcList, pcDst); } list_destroy(pCurList); list_destroy(pSrcList); } int main() { int n = 0; char acCurPath[PATHLEN] = {0}; scanf("%d", &n); scanf("%s", acCurPath); for (int i = 0; i < n; i++) { char acSrcPath[PATHLEN] = {0}; char acDstPath[PATHLEN] = {0}; scanf("%s", acSrcPath); vGetAbsolutePath(acCurPath, acSrcPath, acDstPath); LOG("acDstPath: %s\n\n", acDstPath); printf("%s\n", acDstPath); } return 0; }
-
[C/C++] double fork
double fork 一共有两个作用。
-
生成 daemon 进程。
-
防止产生僵尸进程。
生成 daemon 进程
在 linux 或者 unix 操作系统中在系统的引导的时候会开启很多服务,这些服务就叫做守护进程。
守护进程是脱离于终端并且在后台运行的进程。守护进程脱离于终端是为了避免进程在执行过程中的信息在任何终端上显示并且进程也不会被任何终端所产生的终端信息所打断。
守护进程,也就是通常说的 daemon 进程,是 Linux 中的后台服务进程。它是一个生存期较长的进程,通常独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。
守护进程常常在系统引导装入时启动,在系统关闭时终止。Linux 系统有很多守护进程,大多数服务都是通过守护进程实现的, 同时,守护进程还能完成许多系统任务,例如,作业规划进程 crond、打印进程 lqd 等(这里的结尾字母 d 就是 daemon 的意思)。
由于在 Linux 中,每一个系统与用户进行交流的界面称为终端,每一个从此终端开始运行的进程 都会依附于这个终端, 这个终端就称为这些进程的控制终端,当控制终端被关闭时,相应的进程都会自动关闭。但是守护进程却能够突破这种限制, 它从被执行开始运转,直到整个系统关闭时才退出。如果想让某个进程不因为用户或终端或其他地变化而受到影响,那么就必须把这个进程变成一个守护进程。
创建一个简单的守护进程:
1、创建子进程,父进程退出
这是编写守护进程的第一步。由于守护进程是脱离控制终端的,因此,完成第一步后就会在 Shell 终端里造成一程序已经运行完毕的假象。 之后的所有工作都在子进程中完成,而用户在 Shell 终端里则可以执行其他命令,从而在形式上做到了与控制终端的脱离。 在 Linux 中父进程先于子进程退出会造成子进程成为孤儿进程,而每当系统发现一个孤儿进程时,就会自动由 1 号进程(init)收养它,这样,原先的子进程就会变成 init 进程的子进程。
2、在子进程中创建新会话
这个步骤是创建守护进程中最重要的一步,虽然它的实现非常简单,但它的意义却非常重大。在这里使用的是系统函数 setsid,在具体介绍 setsid 之前,首先要了解两个概念:进程组和会话期 进程组:是一个或多个进程的集合。进程组有进程组 ID 来唯一标识。除了进程号(PID)之外,进程组 ID 也是一个进程的必备属性。 每个进程组都有一个组长进程,其组长进程的进程号等于进程组 ID。且该进程组 ID 不会因组长进程的退出而受到影响。 会话周期:会话期是一个或多个进程组的集合。通常,一个会话开始与用户登录,终止于用户退出,在此期间该用户运行的所有进程都属于这个会话期。 接下来就可以具体介绍 setsid 的相关内容:
(1)setsid 函数作用:
setsid 函数用于创建一个新的会话,并担任该会话组的组长。调用 setsid 有下面的 3 个作用:
让进程摆脱原会话的控制
让进程摆脱原进程组的控制
让进程摆脱原控制终端的控制
那么,在创建守护进程时为什么要调用 setsid 函数呢?由于创建守护进程的第一步调用了 fork 函数来创建子进程,再将父进程退出。 由于在调用了 fork 函数时,子进程全盘拷贝了父进程的会话期、进程组、控制终端等,虽然父进程退出了,但会话期、进程组、控制终端等并没有改变, 因此,还还不是真正意义上的独立开来,而 setsid 函数能够使进程完全独立出来,从而摆脱其他进程的控制。
3、改变当前目录为根目录
这一步也是必要的步骤。使用 fork 创建的子进程继承了父进程的当前工作目录。由于在进程运行中,当前目录所在的文件系统(如“/mnt/usb”)是不能卸载的, 这对以后的使用会造成诸多的麻烦(比如系统由于某种原因要进入但用户模式)。因此,通常的做法是让 “/” 作为守护进程的当前工作目录,这样就可以避免上述的问题, 当然,如有特殊需要,也可以把当前工作目录换成其他的路径,如 /tmp。改变工作目录的常见函数式 chdir。
4、重设文件权限掩码
文件权限掩码是指屏蔽掉文件权限中的对应位。比如,有个文件权限掩码是 050,它就屏蔽了文件组拥有者的可读与可执行权限。 由于使用 fork 函数新建的子进程继承了父进程的文件权限掩码,这就给该子进程使用文件带来了诸多的麻烦。 因此,把文件权限掩码设置为 0,可以大大增强该守护进程的灵活性。设置文件权限掩码的函数是 umask。 在这里,通常的使用方法为 umask(0)。
5、关闭文件描述符
同文件权限码一样,用 fork 函数新建的子进程会从父进程那里继承一些已经打开了的文件。这些被打开的文件可能永远不会被守护进程读写, 但它们一样消耗系统资源,而且可能导致所在的文件系统无法卸下。在上面的第二步之后,守护进程已经与所属的控制终端失去了联系。因此从终端输入的字符不可能达到守护进程,守护进程中用常规方法(如printf)输出的字符也不可能在终端上显示出来。所以,文件描述符为0、1和2 的3个文件(常说的输入、输出和报错)已经失去了存在的价值,也应被关闭。
程序首先调用 fork,并让父进程退出,子进程继续运行。由于子进程是由父进程通过 fork 系统调用派生的,因此子进程继承父进程的进程组号,但它拥有自己的进程号;然后调用 setsid 创建一个新的 session[3],子进程是该 session 中唯一的进程,并且是该 session 的 leader(或者说是 creator),同时也是新创建的进程组的 leader。在调用 setsid 以后,调用进程将不再拥有控制终端。第二次 fork 的目的在于,确保当进程打开终端设备时,也无法获得控制终端,这是因为由 session leader 派生的子进程一定不是session leader,也就无法获得控制终端;接下来的 chdir 系统调用是更改守护进程的工作目录,假设守护进程是在 vfat 文件系统中启动的,如果没有使用 chdir 来更改守护进程的工作目录,那么在守护进程进入后台运行后,此 vfat 文件系统就有可能无法卸载(unmount)。事实上,在 Linux 系统中,即使使用了 chdir 来更改守护进程的工作目录,启动该守护进程的文件系统仍然无法卸载。在实际使用中,chdir 更多地用于满足服务器本身的处理需求;最后的 umask(0) 是为了在守护进程创建自己的文件时,文件权限位不受原有文件创建掩码的权限位的影响。
//Daemonize - BSD double fork approach pid_t pid; int fd; if(g_global.m_bDaemon) { pid = fork(); if(pid < 0) { LOG(EError, Inotify, "fork 1 failed\n"); return EXIT_FAILURE; } if(pid > 0) { _exit(0); } if(setsid() < 0) { LOG(EError, Inotify, "setsid failed failed\n"); return EXIT_FAILURE; } signal(SIGHUP, SIG_IGN); pid = fork(); if(pid < 0) { LOG(EError, Inotify, "fork 2 failed\n"); return EXIT_FAILURE; } if(pid > 0) { _exit(0); } if(chdir("/") < 0) { LOG(EError, Inotify, "chdir to '/' failed\n"); return EXIT_FAILURE; } //Redirect stdin from /dev/null fd = open("/dev/null", O_RDONLY); if(fd != fileno(stdin)) { dup2(fd, fileno(stdin)); close(fd); } //Redirect stdout to a file fd = open(g_global.m_acOutputFile, O_WRONLY | O_CREAT | O_APPEND, 0600); if(fd < 0) { LOG(EError, Inotify, "failed to open out put file: %s\n", g_global.m_acOutputFile); return EXIT_FAILURE; } if(fd != fileno(stdout)) { dup2(fd, fileno(stdout)); close(fd); } //Redirect stderr to /dev/null fd = open("/dev/null", O_WRONLY); if(fd != fileno(stderr)) { dup2(fd, fileno(stderr)); close(fd); } //redirect to stdout ot file, because of buffer exists, if you want to //see result immediately, just call fflush(NULL); printf("STDIN_FILENO=%d, STDOUT_FILENO=%d, STDERR_FILENO=%d\n", STDIN_FILENO, STDOUT_FILENO, STDERR_FILENO); fflush(NULL); }防止产生僵尸进程
首先,要了解什么叫僵尸进程,什么叫孤儿进程,以及服务器进程运行所需要的一些条件。 两次 fork() 就是为了解决这些相关的问题而出现的一种编程方法。
孤儿进程
孤儿进程是指父进程在子进程结束之前死亡(return 或exit)。如下图所示:
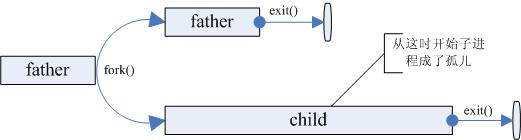
但是孤儿进程并不会像上面画的那样持续很长时间,当系统发现孤儿进程时,init 进程就收养孤儿进程, 成为它的父亲,child 进程 exit 后的资源回收就都由 init 进程来完成。
僵尸进程
僵尸进程是指子进程在父进程之前结束了,但是父进程没有用 wait 或 waitpid 回收子进程。如下图所示:
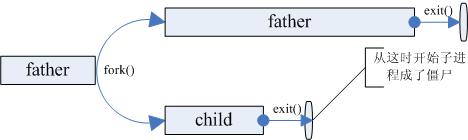
父进程没有用 wait 回收子进程并不说明它不会回收子进程。子进程在结束的时候会给其父进程发送一个 SIGCHILD 信号, 父进程默认是忽略 SIGCHILD 信号的,如果父进程通过 signal() 函数设置了 SIGCHILD 的信号处理函数, 则在信号处理函数中可以回收子进程的资源。
事实上,即便是父进程没有设置 SIGCHILD 的信号处理函数,也没有关系, 因为在父进程结束之前,子进程可以一直保持僵尸状态, 当父进程结束后,init 进程就会负责回收僵尸子进程。
但是,如果父进程是一个服务器进程,一直循环着不退出,那子进程就会一直保持着僵尸状态。 虽然僵尸进程不会占用任何内存资源,但是过多的僵尸进程总还是会影响系统性能的。 黔驴技穷的情况下,该怎么办呢?
这个时候就需要一个英雄来拯救整个世界,它就是两次 fork() 技法。
两次 fork() 技法
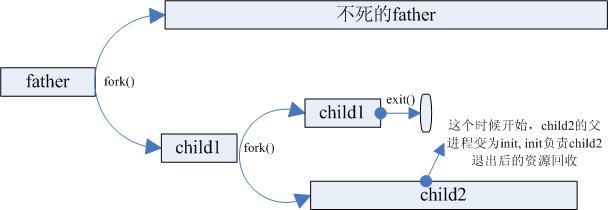
#include <unistd.h> #include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/wait.h> int main() { pid_t pid; pid = fork(); if(pid < 0) { printf("fork 1 failed\n"); return -1; } if(pid == 0) { //first child pid = fork(); if(pid < 0) { printf("fork 2 failed\n"); return -1; } if(pid > 0) { exit(0); //parent from the second fork == first child } //we are the second child. sleep(2); printf("second child, parent id = %d\n", getppid()); exit(0); } //we are the parent. //wait for first child if(waitpid(pid, NULL, 0) != pid) { printf("waitpid error\n"); } return 0; }理所当然,第二个子进程的父进程是进程号为 1 的 init 进程。
参考链接
http://www.linuxidc.com/Linux/2011-08/40590.htm http://roz1987.blog.163.com/blog/static/116392958201011156149507/
-
-
[Design Pattern] Singleton单例模式
CLocker.h
#ifndef CLOCKER_H #define CLOCKER_H #include <pthread.h> class CLocker { public: CLocker() { pthread_mutex_init(&mutex, NULL); } ~CLocker() { pthread_mutex_destroy(&mutex); } void lock() { pthread_mutex_lock(&mutex); } void unlock() { pthread_mutex_unlock(&mutex); } private: pthread_mutex_t mutex; }; #endif懒汉模式
CLazySingleton.h
#ifndef CLAZY_SINGLETON_H #define CLAZY_SINGLETON_H #include <stdio.h> #include "CLocker.h" class CLazySingleton { public: static CLazySingleton * getInstance(); private: CLazySingleton(); ~CLazySingleton(); static CLazySingleton * m_pInstance; static CLocker m_lock; //use class CGarbo to delete m_pInstance class CGarbo { public: ~CGarbo() { printf("CLazySingleton ~CGarbo()\n"); if(CLazySingleton::m_pInstance) { delete CLazySingleton::m_pInstance; } } }; static CGarbo m_garbo; }; #endifCLazySingleton.cpp
#include "CLazySingleton.h" CLazySingleton::CGarbo CLazySingleton::m_garbo; CLazySingleton * CLazySingleton::m_pInstance = NULL; CLocker CLazySingleton::m_lock; CLazySingleton * CLazySingleton::getInstance() { if(NULL == m_pInstance) { m_lock.lock(); if(NULL == m_pInstance) { m_pInstance = new CLazySingleton(); } m_lock.unlock(); } return m_pInstance; } CLazySingleton::CLazySingleton() { printf("CLazySingleton::CLazySingleton()\n"); } CLazySingleton::~CLazySingleton() { printf("CLazySingleton::~CLazySingleton()\n"); }饿汉模式
CHungrySingleton.h
#ifndef CHUNGRY_SINGLETON_H #define CHUNGRY_SINGLETON_H class CHungrySingleton { public: static const CHungrySingleton * getInstance(); private: CHungrySingleton(); ~CHungrySingleton(); static const CHungrySingleton * m_pInstance; }; #endifCHungrySingleton.cpp
#include "CHungrySingleton.h" #include <stdio.h> const CHungrySingleton * CHungrySingleton::m_pInstance = new CHungrySingleton(); const CHungrySingleton * CHungrySingleton::getInstance() { return m_pInstance; } CHungrySingleton::CHungrySingleton() { printf("CHungrySingleton::CHungrySingleton()\n"); } CHungrySingleton::~CHungrySingleton() { printf("CHungrySingleton::~CHungrySingleton()\n"); }main.cpp
#include <stdio.h> #include "CLazySingleton.h" #include "CHungrySingleton.h" int main() { printf("main Singleton\n"); CLazySingleton * pLazy1 = CLazySingleton::getInstance(); CLazySingleton * pLazy2 = CLazySingleton::getInstance(); if(pLazy1 == pLazy1) { printf("Lazy the same\n"); } const CHungrySingleton * pHungry1 = CHungrySingleton::getInstance(); const CHungrySingleton * pHungry2 = CHungrySingleton::getInstance(); if(pHungry1 == pHungry2) { printf("Hungry the same\n"); } return 0; }Makefile
CXX=g++ CFLAGS= TARGET=main OBJS= \ main.o \ CLazySingleton.o \ CHungrySingleton.o %.o : %.cpp $(CXX) -c $(CFLAGS) -fno-strict-aliasing $< -o $@ $(TARGET): $(OBJS) $(CXX) $(CFLAGS) -o $@ $(OBJS) clean: rm -rf *.o $(TARGET)
-
[算法学习][leetcode] 20 Valid Parentheses
https://leetcode.com/problems/valid-parentheses/description/
题目
Given a string containing just the characters ‘(‘, ‘)’, ‘{‘, ‘}’, ‘[’ and ‘]’, determine if the input string is valid.
The brackets must close in the correct order, “()” and “()[]{}” are all valid but “(]” and “([)]” are not.
题目翻译
题目解析
参考答案
#include <stdio.h> #include <stdlib.h> #include <string.h> typedef struct _SStack { char * pcHead; int iSize; int iMaxSize; }SStack; SStack * stack_init(int iLen) { SStack * pStack = (SStack*)malloc(sizeof(SStack)); pStack->pcHead = (char*)malloc(sizeof(iLen)); pStack->iSize = 0; pStack->iMaxSize = iLen; return pStack; } void stack_push(SStack * pStack, char c) { if(pStack->iSize >= pStack->iMaxSize) { return ; } pStack->pcHead[ pStack->iSize ] = c; pStack->iSize++; } char stack_pop(SStack * pStack) { if(pStack->iSize <= 0) { return -1; } pStack->iSize--; return pStack->pcHead[ pStack->iSize ]; } bool stack_isEmpty(SStack * pStack) { return pStack->iSize == 0; } bool isValid(char * s) { int iLen = strlen(s); SStack * pStack = stack_init(iLen); for (int i = 0; i < iLen; i++) { char c = s[i]; if(c == ')') { if(stack_isEmpty(pStack)) { return false; } char top = stack_pop(pStack); if(top != '(') { return false; } } else if(c == ']') { char top = stack_pop(pStack); if(top != '[') { return false; } } else if(c == '}') { char top = stack_pop(pStack); if(top != '{') { return false; } } else { stack_push(pStack, c); } } return stack_isEmpty(pStack); } int main() { printf("%d\n", isValid("[{}]()[[[[(({}))]]]]")); getchar();getchar(); return 0; }
-
[Network] ARP 基础

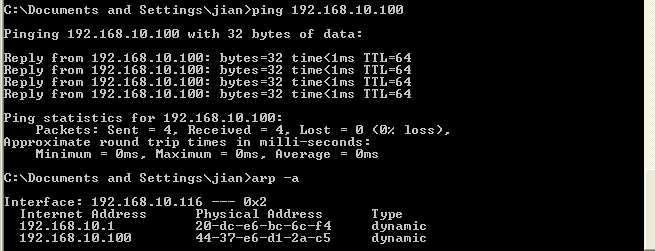

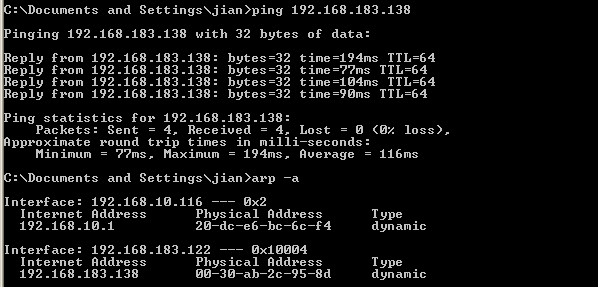
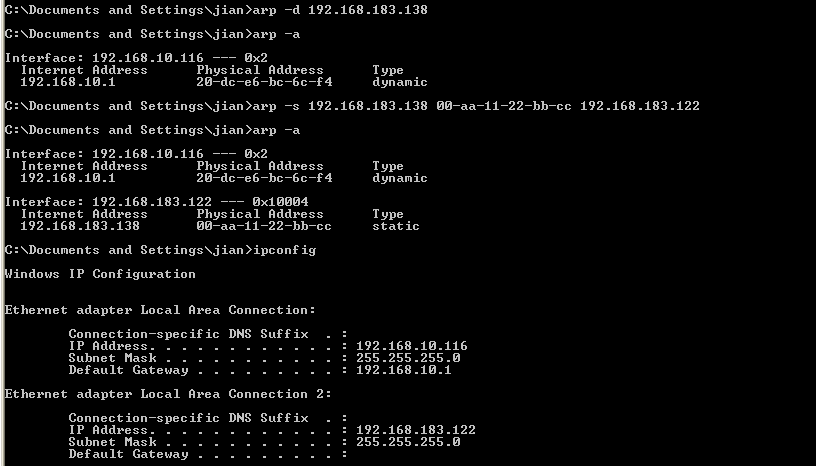
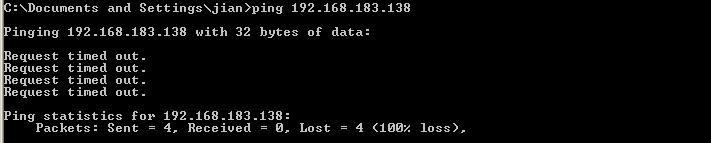
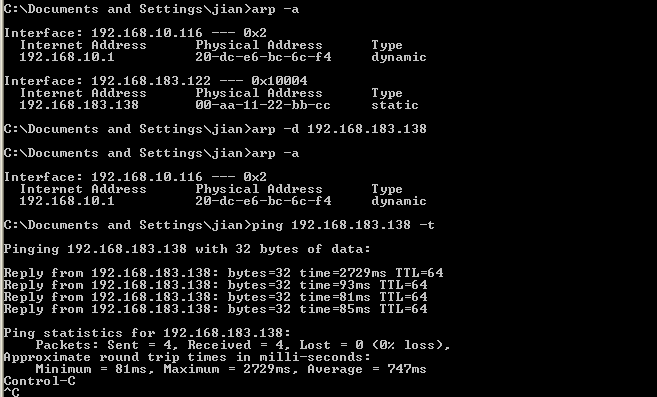
-
[lwip] sys_now and sys_jiffies
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <time.h> typedef unsigned long u32_t; u32_t sys_now(void) { struct timespec ts; clock_gettime(CLOCK_MONOTONIC, &ts); return ts.tv_sec * 1000L + ts.tv_nsec / 1000000L; } u32_t sys_jiffies(void) { struct timespec ts; clock_gettime(CLOCK_MONOTONIC, &ts); return ts.tv_sec * 1000000000L + ts.tv_nsec; } int main() { printf("sys_now = %lu millisecond\n", sys_now()); printf("sys_jiffies = %lu nanosecond\n", sys_jiffies()); return 0; }
- Jekyll 1
- C/C++ 63
- Linux 59
- Web 25
- Qt 12
- Art 124
- Windows 17
- PHP 8
- Network 16
- GDB 3
- lwip 2
- DesignPattern 6
- pthread 6
- CPrimerPlus 9
- tester 3
- GO 75
- openssl 7
- FreeRTOS 9
- 数据库 4
- vk_mj 7
- transdata 3
- Git 7
- lua 20
- nginx 19
- boost 9
- python 18
- google 1
- Redis 1
- miscellanea 11
- life 2
- GCTT 9
- Rust 15
- C语言 2
- TeX 3
- fp 1