Welcome to MDGSF's Blog!
This is my github blog-
[Network] TCP Connection Establishment and Termination
Tree-Way Handshake
The following scenario occurs when a TCP connection is established:
-
The server must be prepared to accept an incoming connection. This is normally done by calling
socket,bind, andlistenand is called a passive open. -
The client issues an active open by calling connect. This causes the client TCP to send a “synchronize” (SYN) segment, which tells the server the client’s initial sequence number for the data that the client will send on the connection. Normally, there is no data sent with the SYN; it just contains an IP header, a TCP header, and possible TCP options (which we will talk about shortly).
-
The server must acknowledge (ACK) the client’s SYN and the server must also send its own SYN containing the initial sequence number for the data that the server will send on the connection. The server sends its SYN and ACK of the client’s SYN in a single segment.
-
The client must acknowledge the server’s SYN.
The minimum number of packets required for this exchange is three; hence, this is called TCP’s three-way handshake. We show the three segments in Figure 2.2.
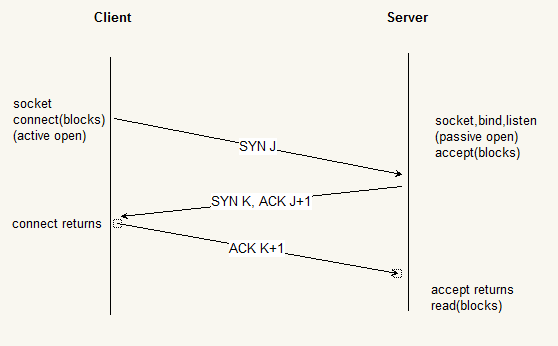
We show the client’s initial sequence number as J and the server’s initial sequence number as K.The acknowledgment number in an ACK is the next expected sequence number for the end sending the ACK. Since a SYN occupies one byte of the sequence number space, the acknowledgment number in the ACK of each SYN is the initial sequence number plus one. Similarly, the ACK of each FIN is the sequence number of the FIN plus one.
TCP Connection Termination
While it takes three segments to establish a connection, it takes four to terminate a connection.
-
One application calls
closefirst, and we say that this end performs the active close. This end’s TCP sends a FIN segment, which means it is finished sending data. -
The other end that receives the FIN performs the passive close. The received FIN is acknowledged by TCP. The receipt of the FIN is also passed to the application as an end-of file (after any data that may have already been queued for the application to receive), since the receipt of the FIN means the application will not receive any additional data on the connection.
-
Sometime later, the application that received the end-of-file will
closeits socket. This causes its TCP to send a FIN. -
The TCP on the system that receives this final FIN (the end that did the active close) acknowledges the FIN.
Since a Fin and an ACK are required in each direction, four segments are normally required. We use the qualifier “normally” because in some scenarios, the FIN in Step 1 is sent with data. Also, the segments in Steps 2 and 3 are both from the end performing the passive close and could be combined into one segment. We show these packets in Figure 2.3.
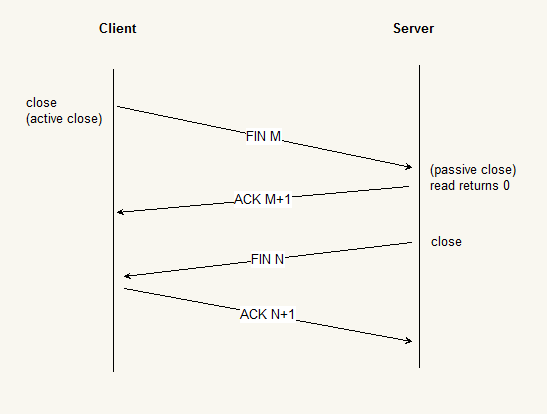
A FIN occupies one byte of sequence number space just line a SYN. Therefore, the ACK of each FIN is the sequence number of the FIN plus one.
Between Steps 2 and 3 it is possible for data to flow from the end doing the passive close to the end doing the active close. This is called a half-close and we will talk about this in detail with the shutdown function in Section 6.6.
The sending of each FIN occurs when a socket is closed. We indicated that the application calls
closefor this to happen, but realize that when a Unix process terminates, either voluntarily(callingexitor having themainfunction return) or involuntarily(receiving a signal that terminates the process), all open descriptors are closed, which will also cause a FIN to be sent on any TCP connection that is still open.Although we show the client in Figure 2.3 performing the active close, either end–the client or the server–can perform the active close. Often the client performs the active close, but with some protocols (notably HTTP/1.0), the server performs the active close.
以上摘自 «Unix Network Programming Vol 1» 2.6节。
-
-
[Network] UDP - User Datagram Protocol
UDP is a simple transport-layer protocol. It is described in RFC 768 [Postel 1980]. The application writes a message to a UDP socket, which is then encapsulated in a UDP datagram, which is then further encapsulated as an IP datagram, which is then sent to its destination. There is no guarantee that a UDP datagram will ever reach its final destination, that order will be preserved across the network, or that datagrams arrive only once.
The problem that we encounter with network programming using UDP is its lack of reliability. If a datagram reaches its final destination but the checksum detects an error, or if the datagram is dropped in the network, it is not delivered to the UDP socket and is not automatically retransmitted. If we want to be certain that a datagram reaches its destination, we can build lots of futures into our application: acknowledgments from the other end, timeouts, retransmissions, and the like.
Each UDP datagram has a length. The length of a datagram is passed to the receiving application along with the data. We have already mentioned that TCP is a byte-stream protocol, without any record boundaries at all, which differs from UDP.
We also say that UDP provides a connectionless service, as there need not be any long-term relationship between a UDP client and server. For example, a UDP client can create a socket and send a datagram to a given server and the immediately send another datagram on the same socket to a different server. Similarly, a UDP server can receive several datagrams on a single UDP socket, each from a different client.
以上摘自 «Unix Network Programming Vol 1» 2.3节。
-
[Network] TCP 状态转换图
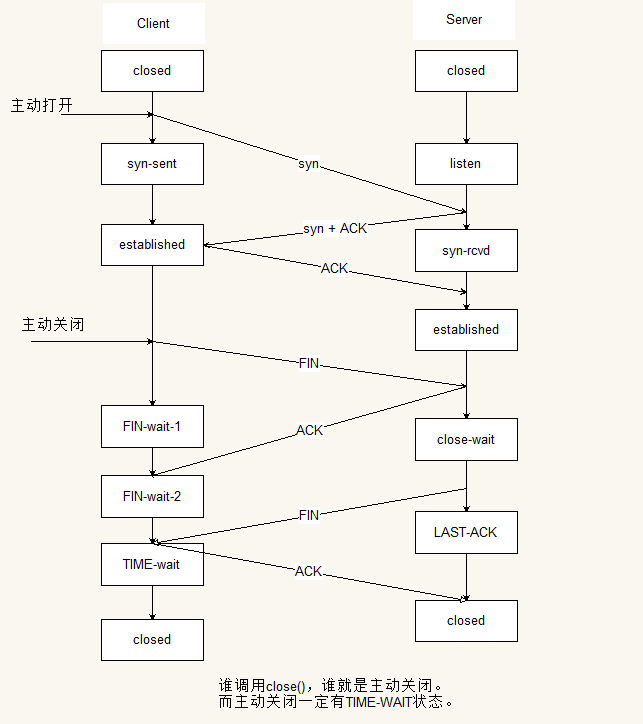
-
[Network] TCP - Transmission Control Protocl
The service provided by TCP to an application is different from the service provided by UDP. TCP is described in RFC 793 [Postel 1981c], and updated by RFC 1323 … . First, TCP provides connections between clients and servers. A TCP client establishes a connection with a given server, exchanges data with that server across the connection, and then terminates the connection.
TCP also provides reliability. When TCP sends data to the other end, it requires an acknowledgment in return. If an acknowledgment is not received, TCP automatically retransmits the data and waits a longer amount of time. After some number of retransmissions, TCP will give up, with the total amount of time spent trying to send data typically between 4 and 10 minutes (depending on the implementation).
Note that TCP does not guarantee that the data will be received by the other endpoint, as this is impossible. It delivers data to the other endpoint if possible, and notifies the user (by giving up on the retransmissions and breaking the connection) if it is not possible. Therefore, TCP cannot be described as a 100% reliable protocol; it provides reliable delivery of data or reliable notification of failure.
TCP contains algorithms to estimate the round-trip time(RTT) between a client and server dynamically so that it knows how long to wait for an acknowledgment. For example, the RTT on a LAN can be milliseconds while across a WAN, it can be seconds. Furthermore, TCP continuously estimates the RTT of a given connection, because the RTT is affected by variations in the network traffic.
TCP also sequences the data by associating a sequence number with every byte that it sends. For example, assume an application writes 2048 bytes to a TCP socket, causing TCP to send two segments, the first containing the data with sequence numbers 1 - 1024 and the second containing the data with sequence numbers 1024 - 2048. (A segment is the unit of data that TCP passes to IP.) If the segments arrive out of order, the receiving TCP will reorder the two segments based on their sequence numbers before passing the data to the receiving application. If TCP receives duplicate data from its peer (say the peer thought a segment was lost and retransmitted it, when it wasn’t really lost, the network was just overloaded), it can detect that the data has been duplicated (from the sequence numbers), and discard the duplicate data.
There is no reliability provided by UDP. UDP itself does not provide anything like acknowledgments, sequence numbers, RTT estimation, timeouts, or retransmissions. If a UDP datagram is duplicated in the network, two copies can be delivered to the receiving host. Also, if a UDP client sends two datagrams to the same destination, they can be reordered by the network and arrive out of order. UDP applications must handle all these cases.
TCP provides flow control. TCP always tells its peer exactly how many bytes of data it is willing to accept from the peer at any one time. This is called the advertised window. At any time, the window is the amount of room currently available in the receive buffer, guaranteeing that the sender cannot overflow the receive buffer. The window changes dynamically over time: As data is received from the sender, the window size decreases, but as the receiving application reads data from the buffer, the window size increases. It is possible for the window to reach 0: when TCP’s receive buffer for a socket is full and it must wait for the application to read data from the buffer before it can take any more data from the peer.
UDP provides no flow control. It is easy for a fast UDP sender to transmit datagrams at a rate that the UDP receiver cannot keep up with, as we will show in Section 8.13.
Finally, a TCP connection is full-duplex. This means that an application can send and receive data in both directions on a given connection at any time. This means that TCP must keep track of state information such as sequence numbers and window sizes for each direction of data flow: sending and receiving. After a full-duplex connection is established, it can be turned into a simplex connection if desired.(see Section 6.6)
UDP can be full-duplex.
以上摘自 «Unix Network Programming Vol 1» 2.4节。
-
[Network] apr non-block
Unix
APR_SO_NONBLOCK timeout value to apr_socket_timeout_set() mode off(==0) t == 0 non-blocking off(==0) t < 0 blocking-forever off(==0) t > 0 blocking-with-timeout off(==1) t == 0 non-blocking off(==1) t < 0 blocking-forever off(==1) t > 0 blocking-with-timeout
Windows
APR_SO_NONBLOCK timeout value to apr_socket_timeout_set() mode off(==0) t == 0 blocking-forever off(==0) t < 0 blocking-forever off(==0) t > 0 blocking-with-timeout off(==1) t == 0 non-blocking off(==1) t < 0 non-blocking off(==1) t > 0 non-blocking The default mode is APR_SO_NONBLOCK==0(off) and APR_SO_TIMEOUT==-1.
Namely, default socket is blocking-forever on both Unix and Windows.
Conclusion (my recommendation):
[a] When you want a non-blocking socket, set it to ‘APR_SO_NONBLOCK==1(on) and timeout==0’.
[b] When you want a blocking-with-timeout socket, set it to ‘APR_SO_NONBLOCK==0(off) and timeout>0’. Note that you must keep the order of calling the APIs. You must call apr_socket_opt_set(sock, APR_SO_NONBLOCK, 1) and then call apr_socket_timeout_set(sock, timeout). Otherwise, on Unix the socket becomes blocking-forever.
[c] When you want a blocking-forever socket, set it to ‘APR_SO_NONBLOCK==0(off) and timeout<0’. In my opinion, we merely need blocking-forever sockets for real application.
Functions
- apr_socket_bind()
- apr_socket_listen()
- apr_socket_recv()
- apr_socket_send()
- apr_socket_accept()
- apr_socket_connect()
We can ignore
apr_socket_bind()andapr_socket_listen(). Because they never block. Simply, these APIs are always non-blocking mode.We can control blocking/non-blocking mode for
apr_socket_recv()andapr_socket_send()as I described above.Here, we consider
apr_socket_accept(). It is almost same as apr_socket_recv()/apr_socket_send(). The mode follows the table in the previous section. Unlike apr_socket_recv()/apr_socket_send(), blocking-forever socket is useful for apr_socket_accept(). It is because that the program might be a server process and might have nothing to do until any client connects to.If we write a mulplexing model code, we need non-blocking socket for listening socket. We check listening socket whether it is ready to read. Readiness to read indicates that any client has connected to the socket. After we know the readiness to read, we just call apr_socket_accept(). Please look at the following example.
apr_socket_accept(&ns, lsock, mp); ...SNIP... /* non-blocking socket. We can't expect that @ns inherits non-blocking mode from @lsock */ apr_socket_opt_set(ns, APR_SO_NONBLOCK, 1); apr_socket_timeout_set(ns, 0);apr_socket_connect()is a bit different from other APIs on blocking/non-blocking mode. It has three modes, blocking-with-system-timeout, blocking-with-timeout, and non-blocking. Unlike other APIs, apr_socket_connect() never blocks forever. The default mode is blocking-with-system-timeout. The timeout value depends on OS, and it is relatively longer, e.g. over one minute. In my opinion, it is not good to use blocking-with-system-timeout mode for real applications, because it is uncontrollable. We have to set either blocking-with-timeout or non-blocking to the mode.To make blocking-with-timeout sockets, we have to set it to ‘APR_SO_NONBLOCK==1(on) and timeout>0’. As you see, this is not same as above. On Unix, we have no problem to specify ‘APR_SO_NONBLOCK==0(off) and timeout>0’. Unfortunatelly, we have a problem on Windows. Setting the mode to ‘APR_SO_NONBLOCK==0(off) and timeout>0’ causes blocking-with-system-timeout sockets on Windows.
Conclusion: If we want blocking-with-timeout socket without portability issues, we should write code as follows:
/* pseudo code: blocking-with-timeout apr_socket_connect() */ apr_socket_opt_set(sock, APR_SO_NONBLOCK, 1); apr_socket_timeout_set(sock, positive_timeout); apr_socket_connect(sock, sa); /* still blocking-with-timeout for other operations, apr_socket_send()/apr_socket_recv() */ apr_socket_opt_set(sock, APR_SO_NONBLOCK, 0); apr_socket_timeout_set(sock, positive_timeout); apr_socket_send(sock, ...); apr_socket_recv(sock, ...);Blocking-with-timeout apr_socket_connect() returns APR_SUCCESS if the connection has been established successfully. Otherwise, it returns an error value. For example, APR_TIMEUP, APR_ECONNREFUSED, or APR_EHOSTUNREACH. If error value is APR_ECONNREFUSED, the server process’s listen(2) backlog is beyond the limit. Please see apr_socket_listen() description above.
链接
http://dev.ariel-networks.com/apr/apr-tutorial/html/apr-tutorial-13.html
-
[数学] 数学常用公式
等差数列:
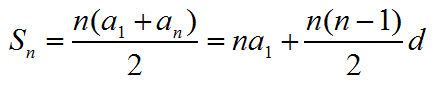
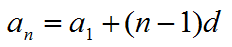
等比数列:
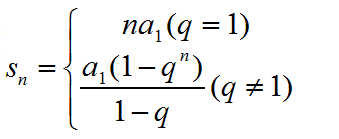
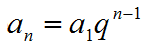
海伦公式
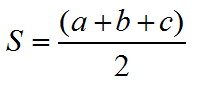
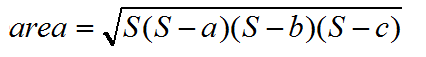
其他
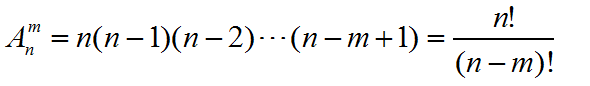
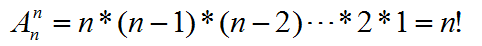
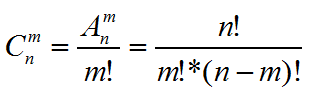
- Jekyll 1
- C/C++ 63
- Linux 59
- Web 25
- Qt 12
- Art 124
- Windows 17
- PHP 8
- Network 16
- GDB 3
- lwip 2
- DesignPattern 6
- pthread 6
- CPrimerPlus 9
- tester 3
- GO 75
- openssl 7
- FreeRTOS 9
- 数据库 4
- vk_mj 7
- transdata 3
- Git 7
- lua 20
- nginx 19
- boost 9
- python 18
- google 1
- Redis 1
- miscellanea 11
- life 2
- GCTT 9
- Rust 15
- C语言 2
- TeX 3
- fp 1