Welcome to MDGSF's Blog!
This is my github blog-
[Linux] Ubuntu 16.04 ip setting
vim /etc/network/interfaces
# interfaces(5) file used by ifup(8) and ifdown(8) auto lo iface lo inet loopback auto enp0s3 iface enp0s3 inet static address 192.168.10.100 gateway 192.168.10.1 netmask 255.255.255.0vim /etc/resolv.conf
nameserver 114.114.114.114 nameserver 8.8.8.8ifdown enp0s3
ifup enp0s3
-
[PHP] 基础语法-标记
如果文件内容是纯 PHP 代码,最好在文件末尾删除 PHP 结束标记。这可以避免在 PHP 结束标记之后万一意外加入了空格或者换行符,会导致 PHP 开始输出这些空白,而脚本中此时并无输出的意图。
<?php echo "Hello world"; // ... more code echo "Last statement"; // 脚本至此结束,并无 PHP 结束标记
1. <?php echo 'if you want to serve XHTML or XML documents, do it like this'; ?> 2. <script language="php"> echo 'some editors (like FrontPage) don\'t like processing instructions'; </script> 3. <? echo 'this is the simplest, an SGML processing instruction'; ?> <?= expression ?> This is a shortcut for "<? echo expression ?>" 4. <% echo 'You may optionally use ASP-style tags'; %> <%= $variable; # This is a shortcut for "<% echo . . ." %>上例中的 1 和 2 中使用的标记总是可用的,其中示例 1 中是最常用,并建议使用的。
短标记(上例 3)仅在通过 php.ini 配置文件中的指令 short_open_tag 打开后才可用,或者在 PHP 编译时加入了 –enable-short-tags 选项。
ASP 风格标记(上例 4)仅在通过 php.ini 配置文件中的指令 asp_tags 打开后才可用。
-
[PHP] 乱码解决方法
1.网页文件head设置编码<meta http-equiv=”Content-Type” content=”text/html; charset=utf-8″ />
2.PHP页面在保存的时候使用utf-8编码保存,可以用记事本或convertz802转换文件
3.在MYSQL中新建数据库的时候数据库 选择UTF-8编码既字符集 设定为 utf-8_unicode_ci(Unicode (多语言), 不区分大小写),
库里面 表table的 整理 设置为 utf-8_general_ci
表里面的每个字段的 整理 都设置为 utf-8_general_ci
4.在PHP连接数据库的时候,也就是mysqli_connect()之后加入
//设置数据的字符集utf-8 $servername = "localhost"; $username = "root"; $password = "password"; $databasename = "form"; $conn = mysqli_connect($servername, $username, $password) or die('Could not connect: '. mysqli_connect_error()); mysqli_select_db($conn, $databasename); mysqli_query($conn, "set names 'utf8'") or die("set names failed: " . mysqli_error($conn)); mysqli_query($conn, "set character_set_client=utf8") or die("set character_set_client failed: " . mysqli_error($conn)); mysqli_query($conn, "set character_set_results=utf8") or die("set character_set_results failed: " . mysqli_error($conn));注意是utf8,不是utf-8 。
如果你的网页编码是gb2312,那就是 SET NAMES GB2312。
但编辑员强烈推荐网页编码、MySQL数据表字符集、PHPmyAdmin都统一使用UTF-8。
以上四点即可实现全站utf-8编码,而且在数据库中也不会有中文乱码。
-
[Windows] vs2008 两个工程文件用同一份代码
在vs2008下,工程的名字叫 pro1.vcproj
将pro1.vcproj 复制为 pro2.vcproj
这个时候,pro1.vcproj 和 pro2.vcproj 就是两个不同的工程,但是共用着同一份代码。
用vs2008打开 pro2.vcproj ,build,有可能会出现下面的错误。按照方法修改了就可以了。
error C2471: cannot update program database vc90.pdb
这个vs2008一个著名的bug。详情可以参见https://connect.microsoft.com/VisualStudio/feedback/ViewFeedback.aspx?FeedbackID=309462
官方现有解决方案如下:
I have found an alternate way for the time beging to avoid C2471 error but it works only in the case of successful release build. for this click Build menu than Configuration manager than create a new setting from release settings. Change following things in your project settings as :
C\C++ | General | Debug Information format | C7 Compatible (/Z7) C\C++ | Code Generation | Enable String Pooling | Yes (/GF) Linker |Debuging |General Debug Info | Yes (/DEBUG)问题:
那么如何在同一份代码里面区分是 pro1.vcproj 还是 pro2.vcproj 在build ?
用宏定义:
#ifdef PRO1 ... //在这里做只有 pro1 需要做的事 #endif #ifdef PRO2 ... //在这里做只有 pro2 需要做的事 #endif问题:
那 PRO1 和 PRO2 这两个宏要从哪里来获取?
在工程目录下建立子目录 type\pro1 和 子目录 type\pro2 ,
在这两个目录下都建立一个 type.h 的文件
//type\pro1\type.h #ifndef PRO1 #define PRO1 #endif//type\pro2\type.h #ifndef PRO2 #define PRO2 #endif然后在 pro1.vcproj 中将 type\pro1\type.h 包含进去。
在 pro2.vcproj 中将 type\pro2\type.h 包含进去。
怎么包含进去?
在工程的属性–> C/C++ –> Additional Include Directories
-
[PHP] 入门 Hello World
软件下载
phpStorm 安装
这里提供的是 PhpStorm-9.0.exe 的安装包,key:
PHPStorm alfred ===== LICENSE BEGIN ===== 35289-12042010 00001Y2rCQfRPrBbQxbXEc9q6u!8wI 96NfhpK1pYy8URPTrXI9IBvLeiEJ2V YmMsNSqoT71VFQX6GPwY9gC0KydFeE ===== LICENSE END =====安装完基本配置:
1.字体大小调整
File –> Settings –> Editor –> Colors & Fonts –> Font
先点击
Save As...按钮,随便保存一个,不然不能修改字体大小。2.显示行号
File –> Settings –> Editor –> General –> Appearance
然后将 Show line numbers 打钩。
3.将编辑的文件加星号标识
File –> Settings –> Editor –> General –> Editor Tabs
勾选 Mark modified tabs with asterisk.
4.UTF-8 Setting
File –> Settings –> Editor –> File Encodings
change all others file encodings to utf-8.
this setting must be restart PhpStorm to take effect.
改个bug:
File –> Default Settings –> Editor –> File Encodings
这里要用 Default Settings ,不然每次新建一个项目的时候,字符编码就又会变成 GBK。
5.给.ctp结尾的文件设置为HTML着色
File –> Settings –> Editor –> File Types
wnmp 安装
一直点击下一步就可以了。
这是安装成功之后的图片:
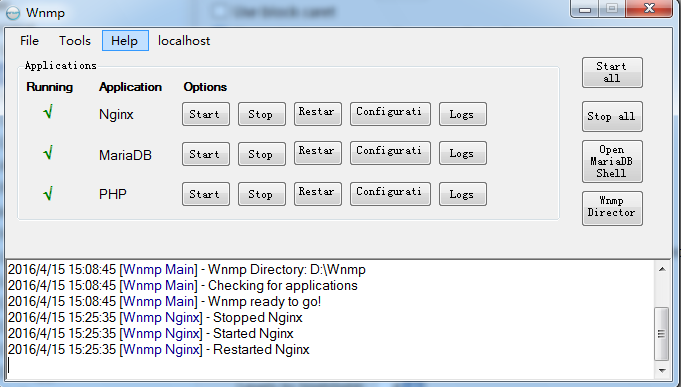
建立第一个PHP程序 Hello World
打开 PhpStorm, File–>New Project…
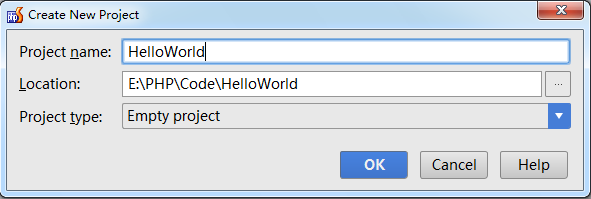
然后新建文件 hello.php
<?php /** * Created by PhpStorm. * User: JIAN.HUANG * Date: 2016/4/15 * Time: 15:12 */ echo "hello world"; ?>开启 wnmp
修改 nginx.conf 配置文件
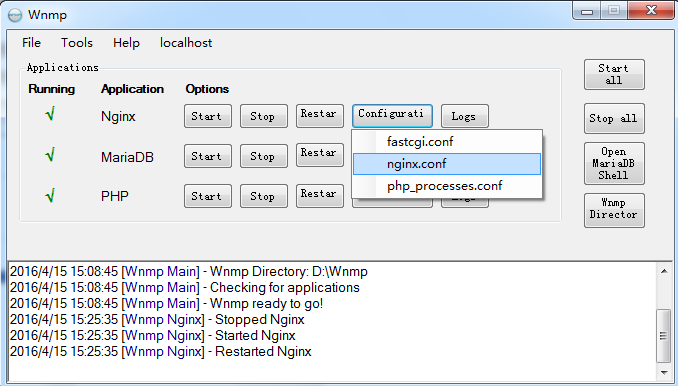
按照上图打开 nginx.conf 配置文件。
# Begin HTTP Server server { listen 80; # IPv4 server_name localhost; ## Parametrization using hostname of access and log filenames. access_log logs/localhost_access.log; error_log logs/localhost_error.log; ## Root and index files. root html; index index.php index.html index.htm; ## If no favicon exists return a 204 (no content error). location = /favicon.ico { try_files $uri =204; log_not_found off; access_log off; } ... ... }找到这段配置信息。将
root html中的html替换成你自己 helloWorld 项目的路径。修改如下:root E:\PHP\Code\HelloWorld;最后,在浏览器中输入
http://localhost/hello.php在界面上看到 hello world 了,就说明成功了。
注意:
如果改为
root E:\PHP\Code;浏览器中输入
http://localhost/HelloWorld/hello.php也是可以的,但是不要这么使用,有的时候会有问题。
-
[字符串] KMP
问题
我们首先要明确,我们要做的事情是什么:给定字符串M和N(M.length >= N.length),请找出N在M中出现的匹配位置。 说白了,就是一个简单的字符串匹配。或许你会说这项工作没什么难度啊,其实只要从头开始比较两个字符串对应字符相等与否,不相等就再从M的下一位开始比较就好了么。是的,这就是一个传统的思路,总结起来其思想如下:
- 当 m[j] == n[i] 时,i与j同时+1;
- 当 m[j] != n[i] 时,j回溯到j-i+1,i回溯到0,然后回到第一步;
- 当 i == len(n) 时,说明匹配完成,输出一个匹配位置,之后回到第二步,查找下一个匹配点。
我们举个例子来演示一下这个比较的方法,给定字串M - abcdabcdabcde,找出N - abcde这个字符串。传统思路解法如下:
i: 0 1 2 3 4 5 6 7 8 9 0 1 2 M: a b c d a b c d a b c d e N: a b c d e // 匹配四位成功后发现a、e不匹配 i: 0 1 2 3 4 5 6 7 8 9 0 1 2 M: a b c d a b c d a b c d e N: a b c d e // 发现 a、b不匹配 i: 0 1 2 3 4 5 6 7 8 9 0 1 2 M: a b c d a b c d a b c d e N: a b c d e // 发现 a、c不匹配 i: 0 1 2 3 4 5 6 7 8 9 0 1 2 M: a b c d a b c d a b c d e N: a b c d e // 发现 a、d不匹配 i: 0 1 2 3 4 5 6 7 8 9 0 1 2 M: a b c d a b c d a b c d e N: a b c d e // 匹配四位成功后发现a、e不匹配 i: 0 1 2 3 4 5 6 7 8 9 0 1 2 M: a b c d a b c d a b c d e N: a b c d e // 发现 a、b不匹配 i: 0 1 2 3 4 5 6 7 8 9 0 1 2 M: a b c d a b c d a b c d e N: a b c d e // 发现 a、c不匹配 i: 0 1 2 3 4 5 6 7 8 9 0 1 2 M: a b c d a b c d a b c d e N: a b c d e // 发现 a、d不匹配 i: 0 1 2 3 4 5 6 7 8 9 0 1 2 M: a b c d a b c d a b c d e N: a b c d e // 匹配成功KMP
目标字符串记为:Target, 长度记为:n。
搜索字符串记为:Pattern, 长度记为:m。
KMP字符串模式匹配通俗点说就是一种在一个字符串中定位另一个串的高效算法。简单匹配算法的时间复杂度为O((n-m+1)m);KMP匹配算法。可以证明它的时间复杂度为O(n+m)。
The Partial Match Table
The key to KMP, of course, is the partial match table. The main obstacle between me and understanding KMP was the fact that I didn’t quite fully grasp what the values in the partial match table really meant. I will now try to explain them in the simplest words possible.
Here’s the partial match table for the pattern “abababca”:
char: | a | b | a | b | a | b | c | a | index: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | value: | 0 | 0 | 1 | 2 | 3 | 4 | 0 | 1 |If I have an eight-character pattern (let’s say “abababca” for the duration of this example), my partial match table will have eight cells. If I’m looking at the eighth and last cell in the table, I’m interested in the entire pattern (“abababca”). If I’m looking at the seventh cell in the table, I’m only interested in the first seven characters in the pattern (“abababc”); the eighth one (“a”) is irrelevant, and can go fall off a building or something. If I’m looking at the sixth cell of the in the table… you get the idea. Notice that I haven’t talked about what each cell means yet, but just what it’s referring to.
Now, in order to talk about the meaning, we need to know about proper prefixes and proper suffixes.
Proper prefix: All the characters in a string, with one or more cut off the end. “S”, “Sn”, “Sna”, and “Snap” are all the proper prefixes of “Snape”.
Proper suffix: All the characters in a string, with one or more cut off the beginning. “agrid”, “grid”, “rid”, “id”, and “d” are all proper suffixes of “Hagrid”.
With this in mind, I can now give the one-sentence meaning of the values in the partial match table:
The length of the longest proper prefix in the (sub)pattern that matches a proper suffix in the same (sub)pattern.
Let’s examine what I mean by that. Say we’re looking in the third cell. As you’ll remember from above, this means we’re only interested in the first three characters (“aba”). In “aba”, there are two proper prefixes (“a” and “ab”) and two proper suffixes (“a” and “ba”). The proper prefix “ab” does not match either of the two proper suffixes. However, the proper prefix “a” matches the proper suffix “a”. Thus, the length of the longest proper prefix that matches a proper suffix, in this case, is 1.
Let’s try it for cell four. Here, we’re interested in the first four characters (“abab”). We have three proper prefixes (“a”, “ab”, and “aba”) and three proper suffixes (“b”, “ab”, and “bab”). This time, “ab” is in both, and is two characters long, so cell four gets value 2.
Just because it’s an interesting example, let’s also try it for cell five, which concerns “ababa”. We have four proper prefixes (“a”, “ab”, “aba”, and “abab”) and four proper suffixes (“a”, “ba”, “aba”, and “baba”). Now, we have two matches: “a” and “aba” are both proper prefixes and proper suffixes. Since “aba” is longer than “a”, it wins, and cell five gets value 3.
Let’s skip ahead to cell seven (the second-to-last cell), which is concerned with the pattern “abababc”. Even without enumerating all the proper prefixes and suffixes, it should be obvious that there aren’t going to be any matches; all the suffixes will end with the letter “c”, and none of the prefixes will. Since there are no matches, cell seven gets 0.
Finally, let’s look at cell eight, which is concerned with the entire pattern (“abababca”). Since they both start and end with “a”, we know the value will be at least 1. However, that’s where it ends; at lengths two and up, all the suffixes contain a c, while only the last prefix (“abababc”) does. This seven-character prefix does not match the seven-character suffix (“bababca”), so cell eight gets 1.
How to use the Partial Match Table
We can use the values in the partial match table to skip ahead (rather than redoing unnecessary old comparisons) when we find partial matches. The formula works like this:
If a partial match of length partial_match_length is found and
table[partial_match_length] > 1, we may skip aheadpartial_match_length - table[partial_match_length - 1]characters.Let’s say we’re matching the pattern “abababca” against the text “bacbababaabcbab”. Here’s our partial match table again for easy reference:
char: | a | b | a | b | a | b | c | a | index: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | value: | 0 | 0 | 1 | 2 | 3 | 4 | 0 | 1 |The first time we get a partial match is here:
bacbababaabcbab | abababcaThis is a partial_match_length of 1. The value at
table[partial_match_length - 1](ortable[0]) is 0, so we don’t get to skip ahead any. The next partial match we get is here:bacbababaabcbab ||||| abababcaThis is a partial_match_length of 5. The value at
table[partial_match_length - 1](ortable[4]) is 3. That means we get to skip aheadpartial_match_length - table[partial_match_length - 1](or5 - table[4]or5 - 3or2) characters:// x denotes a skip bacbababaabcbab xx||| abababcaThis is a partial_match_length of 3. The value at
table[partial_match_length - 1](ortable[2]) is 1. That means we get to skip aheadpartial_match_length - table[partial_match_length - 1](or3 - table[2]or3 - 1or2) characters:// x denotes a skip bacbababaabcbab xx| abababcaAt this point, our pattern is longer than the remaining characters in the text, so we know there’s no match.
如何快速预处理Pattern字符串,得到table数组。
这里,我们将 Pattern字符串记为B[], table 数组记为P[]。
对于字符串 “ababacb”。我们可以通过P[0],P[1],…,P[j-1]的值来获得P[j]的值。
假如我们已经求出了P[0],P[1],P[2]和P[3],看看我们应该怎么求出P[4]和P[5]。
求P[4]。P[3]=2,那么P[4]显然等于P[3]+1。
因为由P[3]=2 ==> 所以B[0,1]和B[2,3]相等, 即B[0]=B[2]='a' B[1]=B[3]='b' 现在又有 B[ P[3] ]==B[4] ==> 即 B[2]==B[4] ==> 所以P[4]=P[3]+1char(B): | a | b | a | b | a | c | b | index: | 0 | 1 | 2 | 3 | 4 | 5 | 6 | value(P): | 0 | 0 | 1 | 2 | 3 | ? | |求P[5]。P[5]也等于P[4]+1吗?显然不是,因为B[ P[4] ]<>B[5]。 那么,我们要考虑“退一步”了。我们考虑P[5]是否有可能由P[4]的情况所包含的子串得到,即是否P[5]=P[ P[4]-1 ]+1。 这里想不通的话可以仔细看一下:
P[4]=3是因为B[0..2]和B[2..4]都是”aba”;而P[2]=1则告诉我们,B[0]、B[2]是”a”。
==>B[0]、B[2]和B[4]都是”a”。
==>即B[0]和B[4]相等。
既然P[5]不能由P[4]得到,或许可以由P[2]得到(如果B[1]恰好和B[5]相等的话,P[5]就等于P[2]+1了)。显然,P[5]也不能通过P[2]得到,因为B[1]<>B[5]。事实上,这样一直推到P[0]也不行,最后,我们得到,P[5]=0。
Code
#include <stdio.h> #include <stdlib.h> #include <string.h> /* * @param pcTarget: the target string. * @param pcPattern: * @return : the index pcPattern founded in pcTarget if success, * -1 if failed. */ int iKMP(const char * pcTarget, const char * pcPattern) { int i = 0; int iTargetLen = strlen(pcTarget); int iPatternLen = strlen(pcPattern); /* build piTable */ int * piTable = (int*)malloc(sizeof(int)*iPatternLen); int iMaxLen = 0; piTable[0] = 0; for (i = 1; i < iPatternLen; i++) { while (iMaxLen>0 && pcPattern[i] != pcPattern[iMaxLen]) iMaxLen = piTable[iMaxLen-1]; if(pcPattern[i] == pcPattern[iMaxLen]) iMaxLen++; piTable[i] = iMaxLen; } /* build piTable end */ int iEndIndex = iTargetLen - iPatternLen; for (i = 0; i <= iEndIndex;) { int j = 0; while (j < iPatternLen && pcTarget[i] == pcPattern[j]) { i++; j++; } if(j == iPatternLen) { return i - iPatternLen; } if(j > 1) { int iSkip = j - piTable[j-1]; i += iSkip; } else { i++; } } return -1; } int main() { const char * pcTarget = "sdfjskafjsfks"; const char * pcPattern = "ska"; printf("%s\n%s\n", pcTarget, pcPattern); printf("%d\n", iKMP(pcTarget, pcPattern) ); return 0; }链接
- Jekyll 1
- C/C++ 63
- Linux 59
- Web 25
- Qt 12
- Art 124
- Windows 17
- PHP 8
- Network 16
- GDB 3
- lwip 2
- DesignPattern 6
- pthread 6
- CPrimerPlus 9
- tester 3
- GO 75
- openssl 7
- FreeRTOS 9
- 数据库 4
- vk_mj 7
- transdata 3
- Git 7
- lua 20
- nginx 19
- boost 9
- python 18
- google 1
- Redis 1
- miscellanea 11
- life 2
- GCTT 9
- Rust 15
- C语言 2
- TeX 3
- fp 1